
主题: Manifold Regularization for Adversarial Robustness
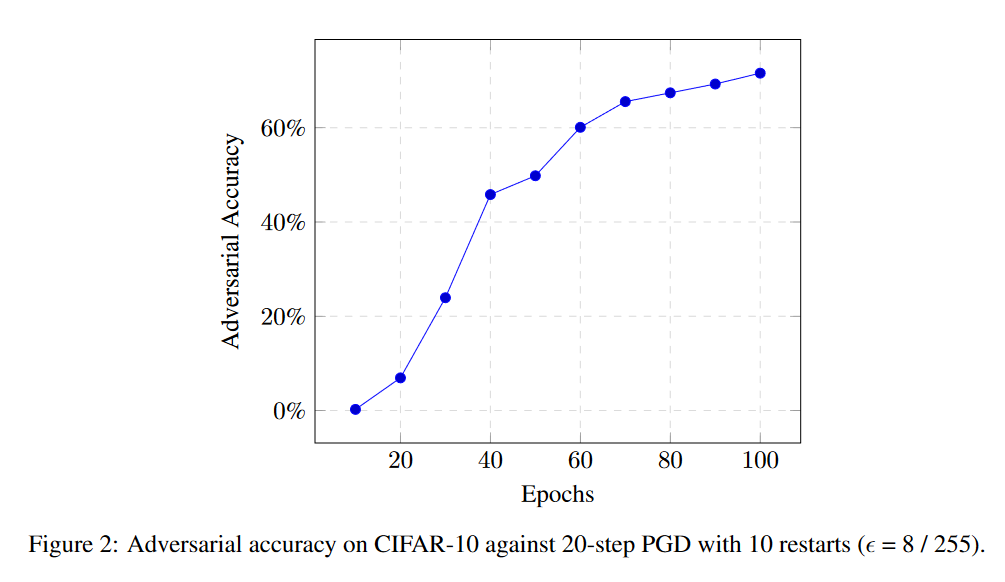
摘要: 流形正则化是一种在输入数据的内在几何上惩罚学习函数复杂性的技术。我们发展了一个与“局部稳定”学习函数的联系,并提出了一个新的正则化项来训练对一类局部扰动稳定的深度神经网络。这些正则化器使我们能够训练一个网络,使其在CIFAR-10上达到70%的最新鲁棒精度,以对抗PGD敌手,使用大小为8/255的ϵ∞扰动。此外,我们的技术不依赖于任何对抗性例子的构造,因此比对抗性训练的标准算法运行速度快几个数量级。
成为VIP会员查看完整内容
相关内容

专知会员服务
50+阅读 · 2020年3月31日
专知会员服务
54+阅读 · 2020年3月5日
专知会员服务
36+阅读 · 2019年11月12日
Arxiv
15+阅读 · 2018年5月24日


相关VIP内容
专知会员服务
50+阅读 · 2020年3月31日
专知会员服务
54+阅读 · 2020年3月5日
专知会员服务
36+阅读 · 2019年11月12日
相关资讯
相关论文
Arxiv
15+阅读 · 2018年5月24日