Ray RLlib: Scalable 降龙十八掌
https://ray.readthedocs.io/en/latest/rllib-algorithms.html#
RLlib Algorithms
High-throughput architectures
Distributed Prioritized Experience Replay (Ape-X)
[paper] [implementation] Ape-X variations of DQN, DDPG, and QMIX (APEX_DQN, APEX_DDPG, APEX_QMIX) use a single GPU learner and many CPU workers for experience collection. Experience collection can scale to hundreds of CPU workers due to the distributed prioritization of experience prior to storage in replay buffers.
Tuned examples: PongNoFrameskip-v4, Pendulum-v0, MountainCarContinuous-v0, {BeamRider,Breakout,Qbert,SpaceInvaders}NoFrameskip-v4.
Atari results @10M steps: more details
| Atari env | RLlib Ape-X 8-workers | Mnih et al Async DQN 16-workers |
|---|---|---|
| BeamRider | 6134 | ~6000 |
| Breakout | 123 | ~50 |
| Qbert | 15302 | ~1200 |
| SpaceInvaders | 686 | ~600 |
Scalability:
| Atari env | RLlib Ape-X 8-workers @1 hour | Mnih et al Async DQN 16-workers @1 hour |
|---|---|---|
| BeamRider | 4873 | ~1000 |
| Breakout | 77 | ~10 |
| Qbert | 4083 | ~500 |
| SpaceInvaders | 646 | ~300 |
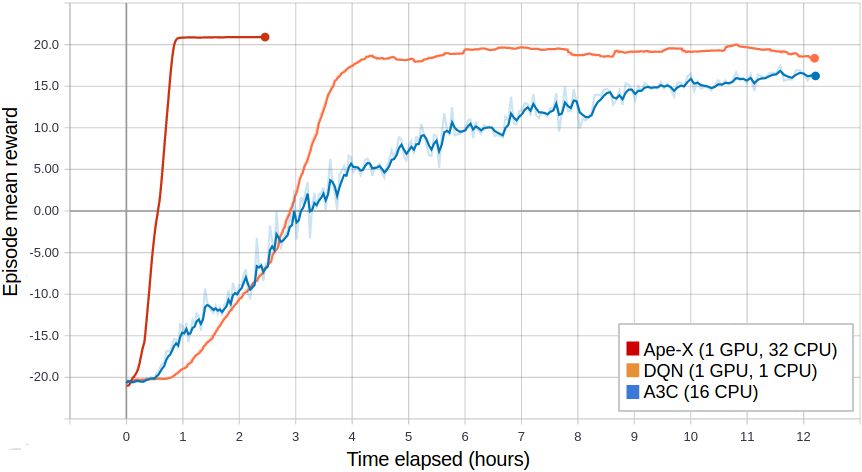
Ape-X using 32 workers in RLlib vs vanilla DQN (orange) and A3C (blue) on PongNoFrameskip-v4.
Ape-X specific configs (see also common configs):
APEX_DEFAULT_CONFIG = merge_dicts( DQN_CONFIG, # see also the options in dqn.py, which are also supported { "optimizer_class": "AsyncReplayOptimizer", "optimizer": merge_dicts( DQN_CONFIG["optimizer"], { "max_weight_sync_delay": 400, "num_replay_buffer_shards": 4, "debug": False }), "n_step": 3, "num_gpus": 1, "num_workers": 32, "buffer_size": 2000000, "learning_starts": 50000, "train_batch_size": 512, "sample_batch_size": 50, "target_network_update_freq": 500000, "timesteps_per_iteration": 25000, "per_worker_exploration": True, "worker_side_prioritization": True, "min_iter_time_s": 30, },)
Importance Weighted Actor-Learner Architecture (IMPALA)
[paper] [implementation] In IMPALA, a central learner runs SGD in a tight loop while asynchronously pulling sample batches from many actor processes. RLlib’s IMPALA implementation uses DeepMind’s reference V-trace code. Note that we do not provide a deep residual network out of the box, but one can be plugged in as a custom model. Multiple learner GPUs and experience replay are also supported.
Tuned examples: PongNoFrameskip-v4, vectorized configuration, multi-gpu configuration, {BeamRider,Breakout,Qbert,SpaceInvaders}NoFrameskip-v4
Atari results @10M steps: more details
| Atari env | RLlib IMPALA 32-workers | Mnih et al A3C 16-workers |
|---|---|---|
| BeamRider | 2071 | ~3000 |
| Breakout | 385 | ~150 |
| Qbert | 4068 | ~1000 |
| SpaceInvaders | 719 | ~600 |
Scalability:
| Atari env | RLlib IMPALA 32-workers @1 hour | Mnih et al A3C 16-workers @1 hour |
|---|---|---|
| BeamRider | 3181 | ~1000 |
| Breakout | 538 | ~10 |
| Qbert | 10850 | ~500 |
| SpaceInvaders | 843 | ~300 |
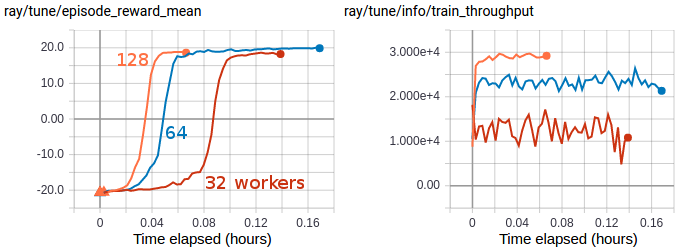
Multi-GPU IMPALA scales up to solve PongNoFrameskip-v4 in ~3 minutes using a pair of V100 GPUs and 128 CPU workers. The maximum training throughput reached is ~30k transitions per second (~120k environment frames per second).
IMPALA-specific configs (see also common configs):
DEFAULT_CONFIG = with_common_config({ # V-trace params (see vtrace.py). "vtrace": True, "vtrace_clip_rho_threshold": 1.0, "vtrace_clip_pg_rho_threshold": 1.0, # System params. # # == Overview of data flow in IMPALA == # 1. Policy evaluation in parallel across `num_workers` actors produces # batches of size `sample_batch_size * num_envs_per_worker`. # 2. If enabled, the replay buffer stores and produces batches of size # `sample_batch_size * num_envs_per_worker`. # 3. If enabled, the minibatch ring buffer stores and replays batches of # size `train_batch_size` up to `num_sgd_iter` times per batch. # 4. The learner thread executes data parallel SGD across `num_gpus` GPUs # on batches of size `train_batch_size`. # "sample_batch_size": 50, "train_batch_size": 500, "min_iter_time_s": 10, "num_workers": 2, # number of GPUs the learner should use. "num_gpus": 1, # set >1 to load data into GPUs in parallel. Increases GPU memory usage # proportionally with the number of buffers. "num_data_loader_buffers": 1, # how many train batches should be retained for minibatching. This conf # only has an effect if `num_sgd_iter > 1`. "minibatch_buffer_size": 1, # number of passes to make over each train batch "num_sgd_iter": 1, # set >0 to enable experience replay. Saved samples will be replayed with # a p:1 proportion to new data samples. "replay_proportion": 0.0, # number of sample batches to store for replay. The number of transitions # saved total will be (replay_buffer_num_slots * sample_batch_size). "replay_buffer_num_slots": 100, # level of queuing for sampling. "max_sample_requests_in_flight_per_worker": 2, # max number of workers to broadcast one set of weights to "broadcast_interval": 1, # Learning params. "grad_clip": 40.0, # either "adam" or "rmsprop" "opt_type": "adam", "lr": 0.0005, "lr_schedule": None, # rmsprop considered "decay": 0.99, "momentum": 0.0, "epsilon": 0.1, # balancing the three losses "vf_loss_coeff": 0.5, "entropy_coeff": -0.01,})
Gradient-based
Advantage Actor-Critic (A2C, A3C)
[paper] [implementation] RLlib implements A2C and A3C using SyncSamplesOptimizer and AsyncGradientsOptimizer respectively for policy optimization. These algorithms scale to up to 16-32 worker processes depending on the environment. Both a TensorFlow (LSTM), and PyTorch version are available.
Tuned examples: PongDeterministic-v4, PyTorch version, {BeamRider,Breakout,Qbert,SpaceInvaders}NoFrameskip-v4
Tip
Consider using IMPALA for faster training with similar timestep efficiency.
Atari results @10M steps: more details
| Atari env | RLlib A2C 5-workers | Mnih et al A3C 16-workers |
|---|---|---|
| BeamRider | 1401 | ~3000 |
| Breakout | 374 | ~150 |
| Qbert | 3620 | ~1000 |
| SpaceInvaders | 692 | ~600 |
A3C-specific configs (see also common configs):
DEFAULT_CONFIG = with_common_config({ # Size of rollout batch "sample_batch_size": 10, # Use PyTorch as backend - no LSTM support "use_pytorch": False, # GAE(gamma) parameter "lambda": 1.0, # Max global norm for each gradient calculated by worker "grad_clip": 40.0, # Learning rate "lr": 0.0001, # Learning rate schedule "lr_schedule": None, # Value Function Loss coefficient "vf_loss_coeff": 0.5, # Entropy coefficient "entropy_coeff": -0.01, # Min time per iteration "min_iter_time_s": 5, # Workers sample async. Note that this increases the effective # sample_batch_size by up to 5x due to async buffering of batches. "sample_async": True,})
Deep Deterministic Policy Gradients (DDPG, TD3)
[paper] [implementation] DDPG is implemented similarly to DQN (below). The algorithm can be scaled by increasing the number of workers, switching to AsyncGradientsOptimizer, or using Ape-X. The improvements from TD3 are available though not enabled by default.
Tuned examples: Pendulum-v0, TD3 configuration, MountainCarContinuous-v0, HalfCheetah-v2
DDPG-specific configs (see also common configs):
DEFAULT_CONFIG = with_common_config({ # === Twin Delayed DDPG (TD3) and Soft Actor-Critic (SAC) tricks === # TD3: https://spinningup.openai.com/en/latest/algorithms/td3.html # twin Q-net "twin_q": False, # delayed policy update "policy_delay": 1, # target policy smoothing # this also forces the use of gaussian instead of OU noise for exploration "smooth_target_policy": False, # gaussian stddev of act noise "act_noise": 0.1, # gaussian stddev of target noise "target_noise": 0.2, # target noise limit (bound) "noise_clip": 0.5, # === Model === # Hidden layer sizes of the policy network "actor_hiddens": [64, 64], # Hidden layers activation of the policy network "actor_hidden_activation": "relu", # Hidden layer sizes of the critic network "critic_hiddens": [64, 64], # Hidden layers activation of the critic network "critic_hidden_activation": "relu", # N-step Q learning "n_step": 1, # === Exploration === # Max num timesteps for annealing schedules. Exploration is annealed from # 1.0 to exploration_fraction over this number of timesteps scaled by # exploration_fraction "schedule_max_timesteps": 100000, # Number of env steps to optimize for before returning "timesteps_per_iteration": 1000, # Fraction of entire training period over which the exploration rate is # annealed "exploration_fraction": 0.1, # Final value of random action probability "exploration_final_eps": 0.02, # OU-noise scale "noise_scale": 0.1, # theta "exploration_theta": 0.15, # sigma "exploration_sigma": 0.2, # Update the target network every `target_network_update_freq` steps. "target_network_update_freq": 0, # Update the target by \tau * policy + (1-\tau) * target_policy "tau": 0.002, # === Replay buffer === # Size of the replay buffer. Note that if async_updates is set, then # each worker will have a replay buffer of this size. "buffer_size": 50000, # If True prioritized replay buffer will be used. "prioritized_replay": True, # Alpha parameter for prioritized replay buffer. "prioritized_replay_alpha": 0.6, # Beta parameter for sampling from prioritized replay buffer. "prioritized_replay_beta": 0.4, # Epsilon to add to the TD errors when updating priorities. "prioritized_replay_eps": 1e-6, # Whether to LZ4 compress observations "compress_observations": False, # === Optimization === # Learning rate for adam optimizer. # Instead of using two optimizers, we use two different loss coefficients "lr": 1e-3, "actor_loss_coeff": 0.1, "critic_loss_coeff": 1.0, # If True, use huber loss instead of squared loss for critic network # Conventionally, no need to clip gradients if using a huber loss "use_huber": False, # Threshold of a huber loss "huber_threshold": 1.0, # Weights for L2 regularization "l2_reg": 1e-6, # If not None, clip gradients during optimization at this value "grad_norm_clipping": None, # How many steps of the model to sample before learning starts. "learning_starts": 1500, # Update the replay buffer with this many samples at once. Note that this # setting applies per-worker if num_workers > 1. "sample_batch_size": 1, # Size of a batched sampled from replay buffer for training. Note that # if async_updates is set, then each worker returns gradients for a # batch of this size. "train_batch_size": 256, # === Parallelism === # Number of workers for collecting samples with. This only makes sense # to increase if your environment is particularly slow to sample, or if # you"re using the Async or Ape-X optimizers. "num_workers": 0, # Optimizer class to use. "optimizer_class": "SyncReplayOptimizer", # Whether to use a distribution of epsilons across workers for exploration. "per_worker_exploration": False, # Whether to compute priorities on workers. "worker_side_prioritization": False, # Prevent iterations from going lower than this time span "min_iter_time_s": 1,})
Deep Q Networks (DQN, Rainbow, Parametric DQN)
[paper] [implementation] RLlib DQN is implemented using the SyncReplayOptimizer. The algorithm can be scaled by increasing the number of workers, using the AsyncGradientsOptimizer for async DQN, or using Ape-X. Memory usage is reduced by compressing samples in the replay buffer with LZ4. All of the DQN improvements evaluated in Rainbow are available, though not all are enabled by default. See also how to use parametric-actions in DQN.
Tuned examples: PongDeterministic-v4, Rainbow configuration, {BeamRider,Breakout,Qbert,SpaceInvaders}NoFrameskip-v4, with Dueling and Double-Q, with Distributional DQN.
Tip
Consider using Ape-X for faster training with similar timestep efficiency.
Atari results @10M steps: more details
| Atari env | RLlib DQN | RLlib Dueling DDQN | RLlib Dist. DQN | Hessel et al. DQN |
|---|---|---|---|---|
| BeamRider | 2869 | 1910 | 4447 | ~2000 |
| Breakout | 287 | 312 | 410 | ~150 |
| Qbert | 3921 | 7968 | 15780 | ~4000 |
| SpaceInvaders | 650 | 1001 | 1025 | ~500 |
DQN-specific configs (see also common configs):
DEFAULT_CONFIG = with_common_config({ # === Model === # Number of atoms for representing the distribution of return. When # this is greater than 1, distributional Q-learning is used. # the discrete supports are bounded by v_min and v_max "num_atoms": 1, "v_min": -10.0, "v_max": 10.0, # Whether to use noisy network "noisy": False, # control the initial value of noisy nets "sigma0": 0.5, # Whether to use dueling dqn "dueling": True, # Whether to use double dqn "double_q": True, # Hidden layer sizes of the state and action value networks "hiddens": [256], # N-step Q learning "n_step": 1, # === Exploration === # Max num timesteps for annealing schedules. Exploration is annealed from # 1.0 to exploration_fraction over this number of timesteps scaled by # exploration_fraction "schedule_max_timesteps": 100000, # Number of env steps to optimize for before returning "timesteps_per_iteration": 1000, # Fraction of entire training period over which the exploration rate is # annealed "exploration_fraction": 0.1, # Final value of random action probability "exploration_final_eps": 0.02, # Update the target network every `target_network_update_freq` steps. "target_network_update_freq": 500, # === Replay buffer === # Size of the replay buffer. Note that if async_updates is set, then # each worker will have a replay buffer of this size. "buffer_size": 50000, # If True prioritized replay buffer will be used. "prioritized_replay": True, # Alpha parameter for prioritized replay buffer. "prioritized_replay_alpha": 0.6, # Beta parameter for sampling from prioritized replay buffer. "prioritized_replay_beta": 0.4, # Fraction of entire training period over which the beta parameter is # annealed "beta_annealing_fraction": 0.2, # Final value of beta "final_prioritized_replay_beta": 0.4, # Epsilon to add to the TD errors when updating priorities. "prioritized_replay_eps": 1e-6, # Whether to LZ4 compress observations "compress_observations": True, # === Optimization === # Learning rate for adam optimizer "lr": 5e-4, # Adam epsilon hyper parameter "adam_epsilon": 1e-8, # If not None, clip gradients during optimization at this value "grad_norm_clipping": 40, # How many steps of the model to sample before learning starts. "learning_starts": 1000, # Update the replay buffer with this many samples at once. Note that # this setting applies per-worker if num_workers > 1. "sample_batch_size": 4, # Size of a batched sampled from replay buffer for training. Note that # if async_updates is set, then each worker returns gradients for a # batch of this size. "train_batch_size": 32, # === Parallelism === # Number of workers for collecting samples with. This only makes sense # to increase if your environment is particularly slow to sample, or if # you"re using the Async or Ape-X optimizers. "num_workers": 0, # Optimizer class to use. "optimizer_class": "SyncReplayOptimizer", # Whether to use a distribution of epsilons across workers for exploration. "per_worker_exploration": False, # Whether to compute priorities on workers. "worker_side_prioritization": False, # Prevent iterations from going lower than this time span "min_iter_time_s": 1,})
Policy Gradients
[paper] [implementation] We include a vanilla policy gradients implementation as an example algorithm. This is usually outperformed by PPO.
Tuned examples: CartPole-v0
PG-specific configs (see also common configs):
DEFAULT_CONFIG = with_common_config({ # No remote workers by default "num_workers": 0, # Learning rate "lr": 0.0004,})
Proximal Policy Optimization (PPO)
[paper] [implementation] PPO’s clipped objective supports multiple SGD passes over the same batch of experiences. RLlib’s multi-GPU optimizer pins that data in GPU memory to avoid unnecessary transfers from host memory, substantially improving performance over a naive implementation. RLlib’s PPO scales out using multiple workers for experience collection, and also with multiple GPUs for SGD.
Tuned examples: Humanoid-v1, Hopper-v1, Pendulum-v0, PongDeterministic-v4, Walker2d-v1, {BeamRider,Breakout,Qbert,SpaceInvaders}NoFrameskip-v4
Atari results: more details
| Atari env | RLlib PPO @10M | RLlib PPO @25M | Baselines PPO @10M |
|---|---|---|---|
| BeamRider | 2807 | 4480 | ~1800 |
| Breakout | 104 | 201 | ~250 |
| Qbert | 11085 | 14247 | ~14000 |
| SpaceInvaders | 671 | 944 | ~800 |
Scalability:
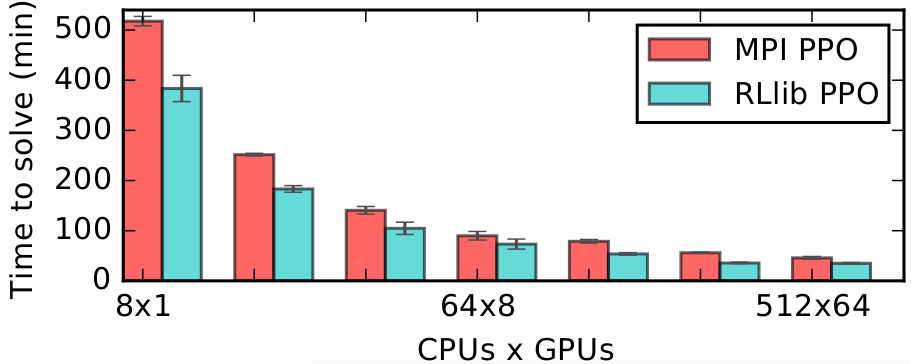
RLlib’s multi-GPU PPO scales to multiple GPUs and hundreds of CPUs on solving the Humanoid-v1 task. Here we compare against a reference MPI-based implementation.
PPO-specific configs (see also common configs):
DEFAULT_CONFIG = with_common_config({ # If true, use the Generalized Advantage Estimator (GAE) # with a value function, see https://arxiv.org/pdf/1506.02438.pdf. "use_gae": True, # GAE(lambda) parameter "lambda": 1.0, # Initial coefficient for KL divergence "kl_coeff": 0.2, # Size of batches collected from each worker "sample_batch_size": 200, # Number of timesteps collected for each SGD round "train_batch_size": 4000, # Total SGD batch size across all devices for SGD "sgd_minibatch_size": 128, # Number of SGD iterations in each outer loop "num_sgd_iter": 30, # Stepsize of SGD "lr": 5e-5, # Learning rate schedule "lr_schedule": None, # Share layers for value function "vf_share_layers": False, # Coefficient of the value function loss "vf_loss_coeff": 1.0, # Coefficient of the entropy regularizer "entropy_coeff": 0.0, # PPO clip parameter "clip_param": 0.3, # Clip param for the value function. Note that this is sensitive to the # scale of the rewards. If your expected V is large, increase this. "vf_clip_param": 10.0, # Target value for KL divergence "kl_target": 0.01, # Whether to rollout "complete_episodes" or "truncate_episodes" "batch_mode": "truncate_episodes", # Which observation filter to apply to the observation "observation_filter": "MeanStdFilter", # Uses the sync samples optimizer instead of the multi-gpu one. This does # not support minibatches. "simple_optimizer": False, # (Deprecated) Use the sampling behavior as of 0.6, which launches extra # sampling tasks for performance but can waste a large portion of samples. "straggler_mitigation": False,})
Derivative-free
Augmented Random Search (ARS)
[paper] [implementation] ARS is a random search method for training linear policies for continuous control problems. Code here is adapted from https://github.com/modestyachts/ARS to integrate with RLlib APIs.
Tuned examples: CartPole-v0, Swimmer-v2
ARS-specific configs (see also common configs):
DEFAULT_CONFIG = with_common_config({ "noise_stdev": 0.02, # std deviation of parameter noise "num_rollouts": 32, # number of perturbs to try "rollouts_used": 32, # number of perturbs to keep in gradient estimate "num_workers": 2, "sgd_stepsize": 0.01, # sgd step-size "observation_filter": "MeanStdFilter", "noise_size": 250000000, "eval_prob": 0.03, # probability of evaluating the parameter rewards "report_length": 10, # how many of the last rewards we average over "offset": 0,})
Evolution Strategies
[paper] [implementation] Code here is adapted from https://github.com/openai/evolution-strategies-starter to execute in the distributed setting with Ray.
Tuned examples: Humanoid-v1
Scalability:
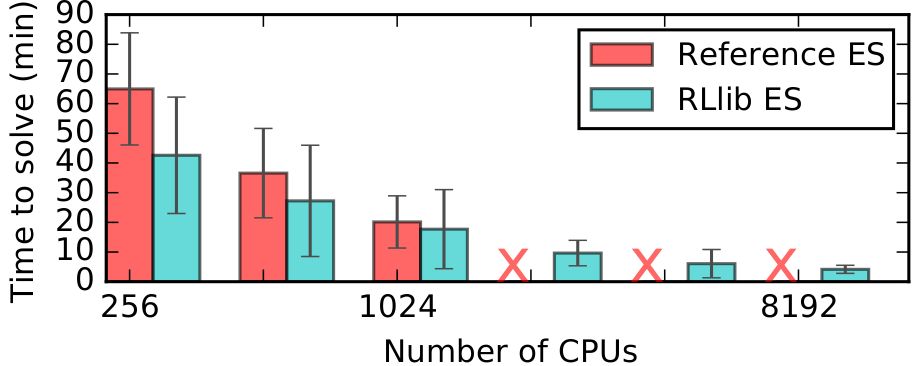
RLlib’s ES implementation scales further and is faster than a reference Redis implementation on solving the Humanoid-v1 task.
ES-specific configs (see also common configs):
DEFAULT_CONFIG = with_common_config({ "l2_coeff": 0.005, "noise_stdev": 0.02, "episodes_per_batch": 1000, "train_batch_size": 10000, "eval_prob": 0.003, "return_proc_mode": "centered_rank", "num_workers": 10, "stepsize": 0.01, "observation_filter": "MeanStdFilter", "noise_size": 250000000, "report_length": 10,})
QMIX Monotonic Value Factorisation (QMIX, VDN, IQN)
[paper] [implementation] Q-Mix is a specialized multi-agent algorithm. Code here is adapted from https://github.com/oxwhirl/pymarl_alpha to integrate with RLlib multi-agent APIs. To use Q-Mix, you must specify an agent grouping in the environment (see the two-step game example). Currently, all agents in the group must be homogeneous. The algorithm can be scaled by increasing the number of workers or using Ape-X.
Q-Mix is implemented in PyTorch and is currently experimental.
Tuned examples: Two-step game
QMIX-specific configs (see also common configs):
DEFAULT_CONFIG = with_common_config({ # === QMix === # Mixing network. Either "qmix", "vdn", or None "mixer": "qmix", # Size of the mixing network embedding "mixing_embed_dim": 32, # Whether to use Double_Q learning "double_q": True, # Optimize over complete episodes by default. "batch_mode": "complete_episodes", # === Exploration === # Max num timesteps for annealing schedules. Exploration is annealed from # 1.0 to exploration_fraction over this number of timesteps scaled by # exploration_fraction "schedule_max_timesteps": 100000, # Number of env steps to optimize for before returning "timesteps_per_iteration": 1000, # Fraction of entire training period over which the exploration rate is # annealed "exploration_fraction": 0.1, # Final value of random action probability "exploration_final_eps": 0.02, # Update the target network every `target_network_update_freq` steps. "target_network_update_freq": 500, # === Replay buffer === # Size of the replay buffer in steps. "buffer_size": 10000, # === Optimization === # Learning rate for adam optimizer "lr": 0.0005, # RMSProp alpha "optim_alpha": 0.99, # RMSProp epsilon "optim_eps": 0.00001, # If not None, clip gradients during optimization at this value "grad_norm_clipping": 10, # How many steps of the model to sample before learning starts. "learning_starts": 1000, # Update the replay buffer with this many samples at once. Note that # this setting applies per-worker if num_workers > 1. "sample_batch_size": 4, # Size of a batched sampled from replay buffer for training. Note that # if async_updates is set, then each worker returns gradients for a # batch of this size. "train_batch_size": 32, # === Parallelism === # Number of workers for collecting samples with. This only makes sense # to increase if your environment is particularly slow to sample, or if # you"re using the Async or Ape-X optimizers. "num_workers": 0, # Optimizer class to use. "optimizer_class": "SyncBatchReplayOptimizer", # Whether to use a distribution of epsilons across workers for exploration. "per_worker_exploration": False, # Whether to compute priorities on workers. "worker_side_prioritization": False, # Prevent iterations from going lower than this time span "min_iter_time_s": 1, # === Model === "model": { "lstm_cell_size": 64, "max_seq_len": 999999, },})


