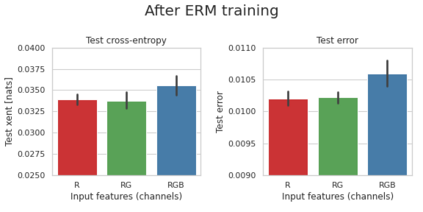
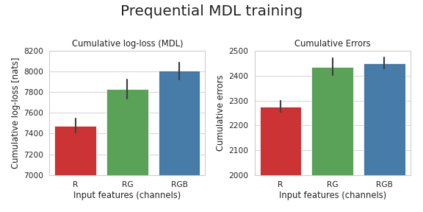
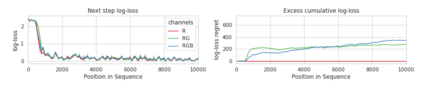
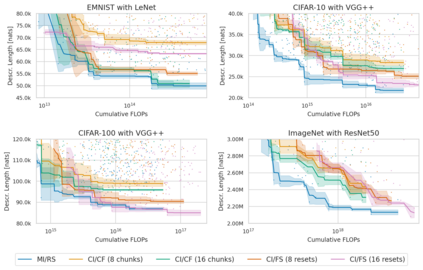
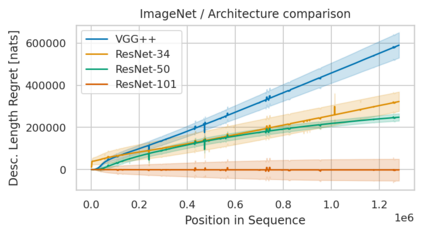
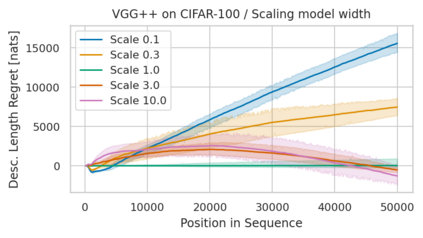
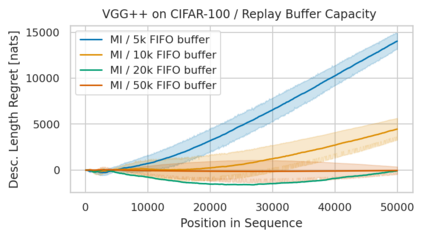
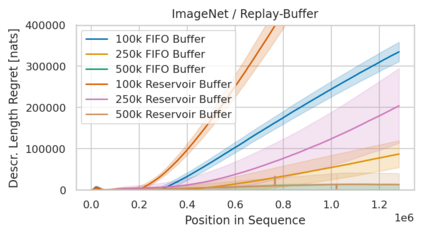
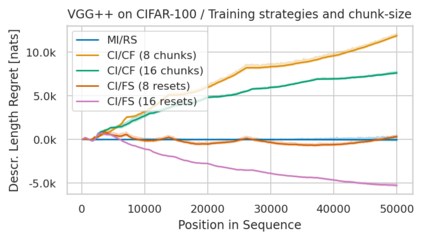
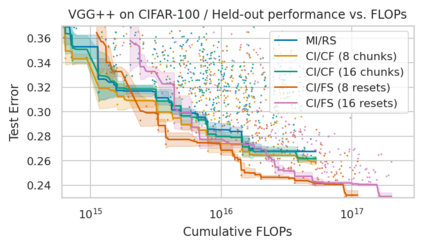
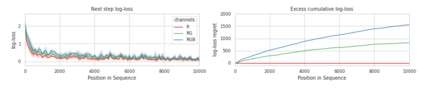
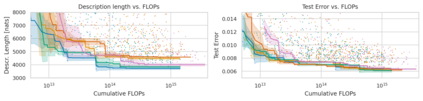
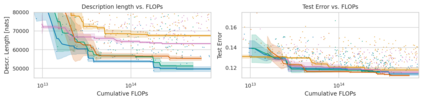
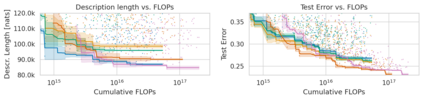
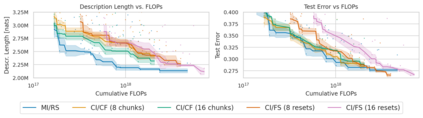
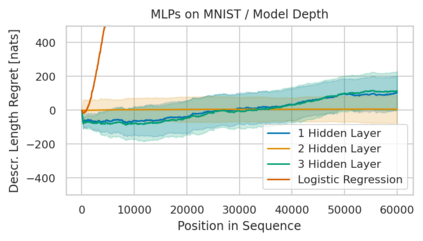
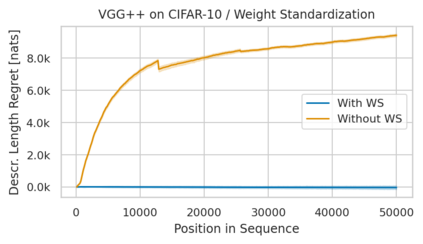
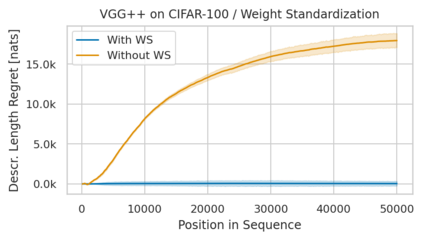
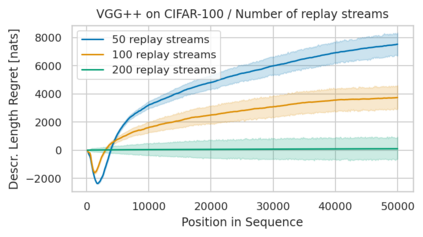
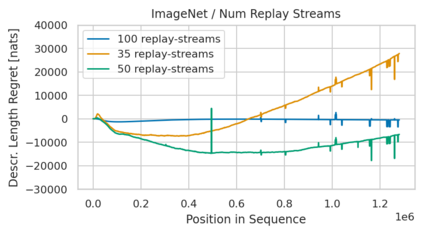
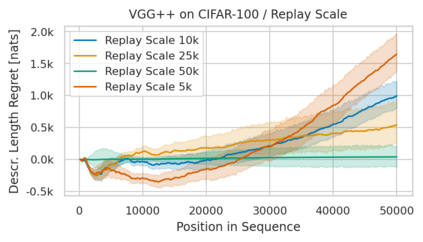
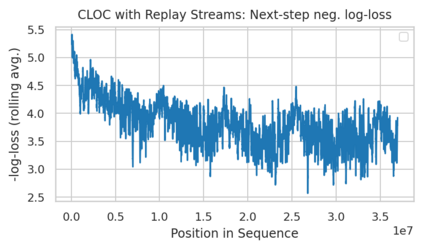
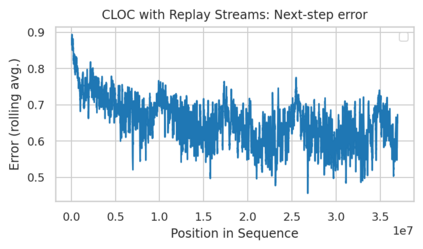
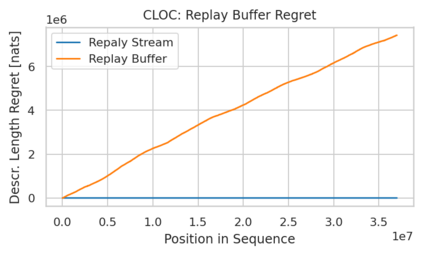
Minimum Description Length (MDL) provides a framework and an objective for principled model evaluation. It formalizes Occam's Razor and can be applied to data from non-stationary sources. In the prequential formulation of MDL, the objective is to minimize the cumulative next-step log-loss when sequentially going through the data and using previous observations for parameter estimation. It thus closely resembles a continual- or online-learning problem. In this study, we evaluate approaches for computing prequential description lengths for image classification datasets with neural networks. Considering the computational cost, we find that online-learning with rehearsal has favorable performance compared to the previously widely used block-wise estimation. We propose forward-calibration to better align the models predictions with the empirical observations and introduce replay-streams, a minibatch incremental training technique to efficiently implement approximate random replay while avoiding large in-memory replay buffers. As a result, we present description lengths for a suite of image classification datasets that improve upon previously reported results by large margins.
翻译:最小描述长度( MDL) 提供了一个框架和有原则的模型评估目标。 它将 Occam 的 Razor 正式化, 并可用于来自非静止来源的数据。 在MDL 的预先配方中, 目标是在连续通过数据并使用先前的观察进行参数估计时, 最大限度地减少累积的下一步记录损失。 因此, 它与一个持续或在线学习的问题非常相似。 在这次研究中, 我们评估了用于计算神经网络图像分类数据集的预数描述长度的方法。 考虑到计算成本, 我们发现, 在线练习学习与以往广泛使用的区块估计相比, 具有更有利的性能。 我们提出了前方校准, 以便更好地将模型预测与经验性观测保持一致, 并引入回放流, 这是一种小型的递增培训技术, 以高效实施近似随机重播, 同时避免大型的模拟回放缓冲。 因此, 我们为一组图像分类数据集提供了描述长度, 根据以往报告的大边距改进的结果, 。