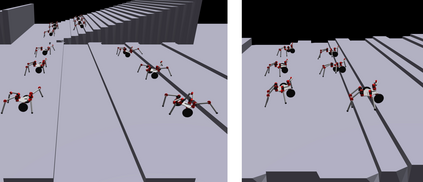
Control policy learning for modular robot locomotion has previously been limited to proprioceptive feedback and flat terrain. This paper develops policies for modular systems with vision traversing more challenging environments. These modular robots can be reconfigured to form many different designs, where each design needs a controller to function. Though one could create a policy for individual designs and environments, such an approach is not scalable given the wide range of potential designs and environments. To address this challenge, we create a visual-motor policy that can generalize to both new designs and environments. The policy itself is modular, in that it is divided into components, each of which corresponds to a type of module (e.g., a leg, wheel, or body). The policy components can be recombined during training to learn to control multiple designs. We develop a deep reinforcement learning algorithm where visual observations are input to a modular policy interacting with multiple environments at once. We apply this algorithm to train robots with combinations of legs and wheels, then demonstrate the policy controlling real robots climbing stairs and curbs.
翻译:模块化机器人移动控制政策学习以前仅限于自行感知反馈和平坦地形。 本文为具有视觉环绕环境的模块化系统制定了政策。 这些模块化机器人可以重新配置成许多不同的设计, 每个设计都需要一个控制器来运行。 尽管可以为单个设计和环境创建政策, 但鉴于潜在的设计和环境范围广泛, 这种方法无法伸缩。 为了应对这一挑战, 我们创建了一个视觉运动政策, 既可以推广到新的设计和环境。 政策本身是模块化的, 因为它分为一个组件, 每个组件都对应模块的类型( 如腿、 轮或身体 ) 。 政策组成部分可以在培训中重新组合, 以学习控制多重设计。 我们开发了深度强化学习算法, 将视觉观察纳入模块政策, 与多种环境同时互动。 我们用这种算法来培训双腿和轮组合的机器人, 然后演示控制真正机器人攀登楼梯和阻挡的政策 。