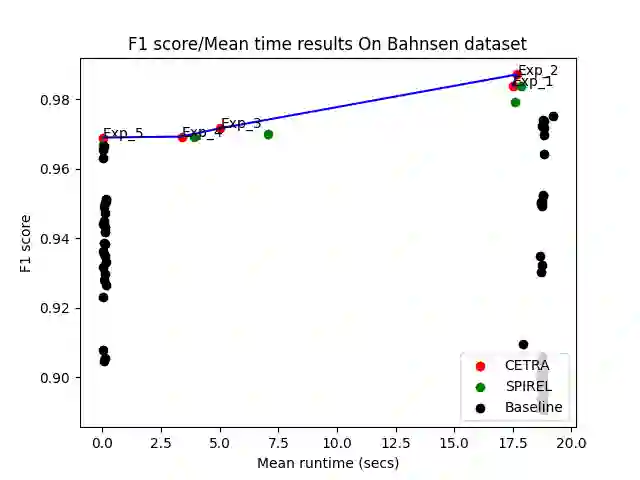
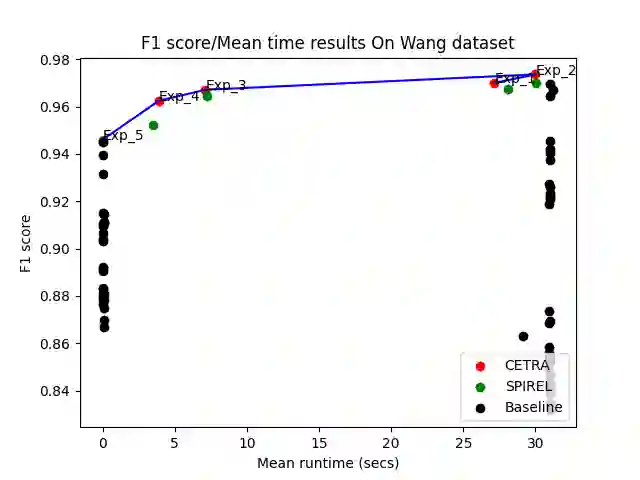
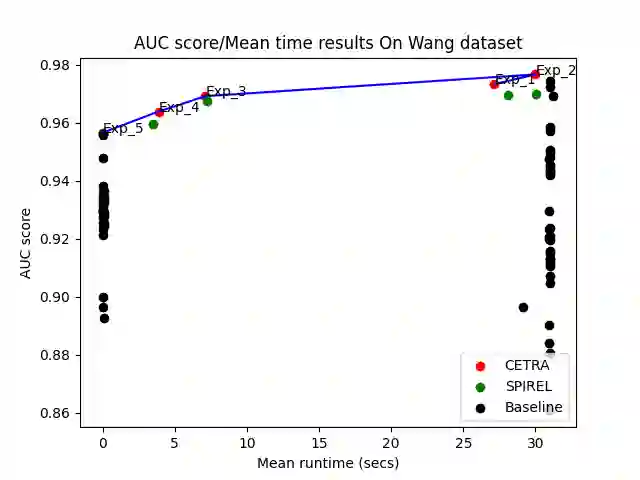
Many challenging real-world problems require the deployment of ensembles multiple complementary learning models to reach acceptable performance levels. While effective, applying the entire ensemble to every sample is costly and often unnecessary. Deep Reinforcement Learning (DRL) offers a cost-effective alternative, where detectors are dynamically chosen based on the output of their predecessors, with their usefulness weighted against their computational cost. Despite their potential, DRL-based solutions are not widely used in this capacity, partly due to the difficulties in configuring the reward function for each new task, the unpredictable reactions of the DRL agent to changes in the data, and the inability to use common performance metrics (e.g., TPR/FPR) to guide the algorithm's performance. In this study we propose methods for fine-tuning and calibrating DRL-based policies so that they can meet multiple performance goals. Moreover, we present a method for transferring effective security policies from one dataset to another. Finally, we demonstrate that our approach is highly robust against adversarial attacks.
翻译:许多具有挑战性的现实问题要求部署多种互补学习模式,以达到可接受的业绩水平。虽然有效,但将整个组合应用到每个样本中是昂贵的,而且往往没有必要。深强化学习(DRL)提供了一种具有成本效益的替代方法,即根据其前身的产出动态地选择探测器,其效用与计算成本相权衡。尽管存在潜力,但基于DRL的解决方案在这种能力上并没有被广泛使用,部分原因是在为每项新任务配置奖励功能方面遇到困难,DRL代理对数据变化作出不可预测的反应,以及无法使用通用性能指标(例如TRP/FPR)来指导算法的性能。在这项研究中,我们提出了微调和校准基于DRL的政策的方法,以便它们能够达到多重性能目标。此外,我们提出了一种将有效的安全政策从一个数据集转移到另一个数据集的方法。最后,我们证明我们的方法对于对抗敌对性攻击非常有力。