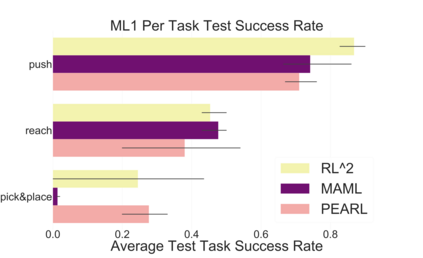
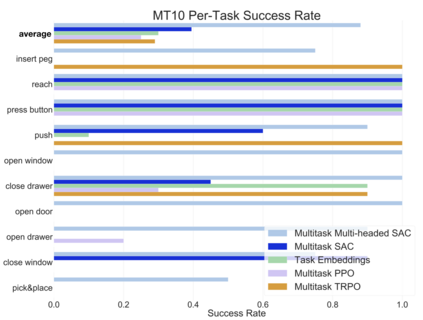
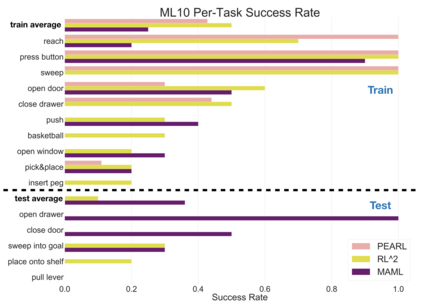
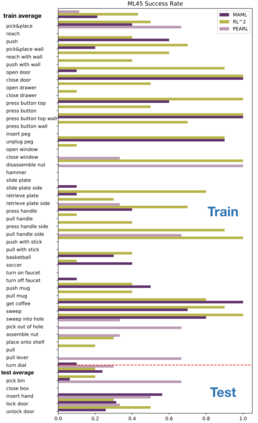
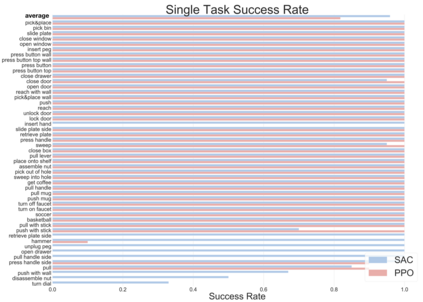
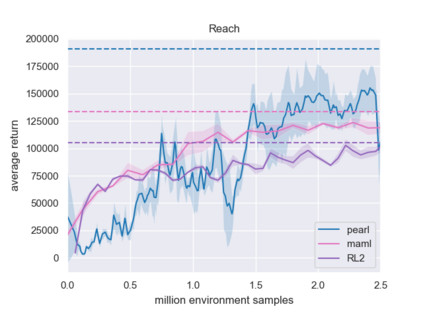
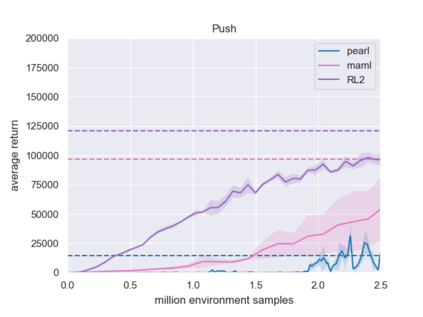
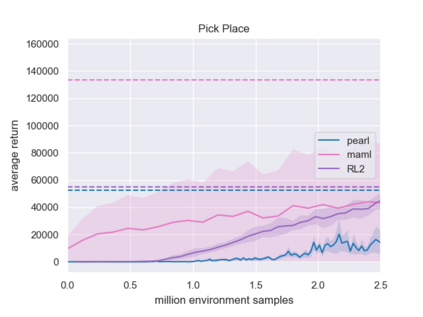
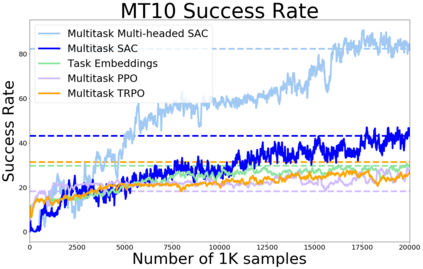
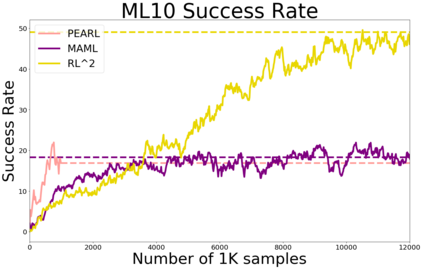
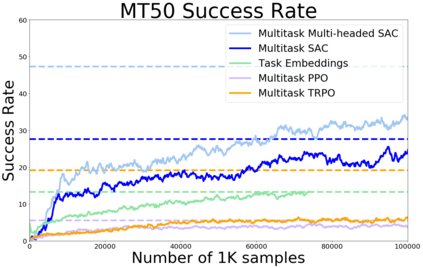
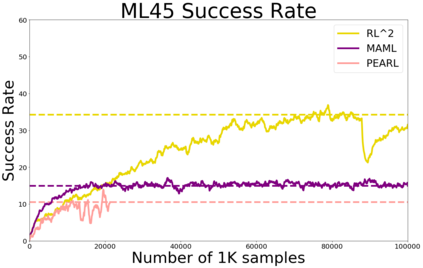
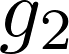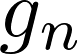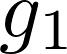Meta-reinforcement learning algorithms can enable robots to acquire new skills much more quickly, by leveraging prior experience to learn how to learn. However, much of the current research on meta-reinforcement learning focuses on task distributions that are very narrow. For example, a commonly used meta-reinforcement learning benchmark uses different running velocities for a simulated robot as different tasks. When policies are meta-trained on such narrow task distributions, they cannot possibly generalize to more quickly acquire entirely new tasks. Therefore, if the aim of these methods is to enable faster acquisition of entirely new behaviors, we must evaluate them on task distributions that are sufficiently broad to enable generalization to new behaviors. In this paper, we propose an open-source simulated benchmark for meta-reinforcement learning and multi-task learning consisting of 50 distinct robotic manipulation tasks. Our aim is to make it possible to develop algorithms that generalize to accelerate the acquisition of entirely new, held-out tasks. We evaluate 6 state-of-the-art meta-reinforcement learning and multi-task learning algorithms on these tasks. Surprisingly, while each task and its variations (e.g., with different object positions) can be learned with reasonable success, these algorithms struggle to learn with multiple tasks at the same time, even with as few as ten distinct training tasks. Our analysis and open-source environments pave the way for future research in multi-task learning and meta-learning that can enable meaningful generalization, thereby unlocking the full potential of these methods.
翻译:元加强学习算法可以让机器人更快地获得新的技能,办法是利用先前的经验学习如何学习。然而,目前关于元加强学习的研究大多侧重于非常狭窄的任务分布。例如,通常使用的元加强学习基准将模拟机器人的不同运行速度作为不同的任务。当政策在这种狭窄的任务分布上经过元化训练时,它们可能无法推广到更迅速地获得全新的任务。因此,如果这些方法的目的是为了更快地获得全新的行为,我们必须评估它们具有足够广泛意义的任务分布,以便能够对新的行为进行概括化。在本文中,我们提出一个用于元加强学习和多任务学习的公开源模拟基准,包括50项不同的机械操纵任务。我们的目标是能够开发总算算算法,以加速获得全新、已搁置的任务。我们评价6个最先进的元加强学习和多任务分布,我们必须评估它们是否足够广泛的任务分布,以便能够对新的行为进行概括化的分布进行广泛,从而能够对新的行为进行概括化的分布进行概括化分析。我们提出一个公开的源构建模拟基准,这些任务在学习过程中可以学习各种不同的任务进行不同的学习,同时进行不同的学习。