
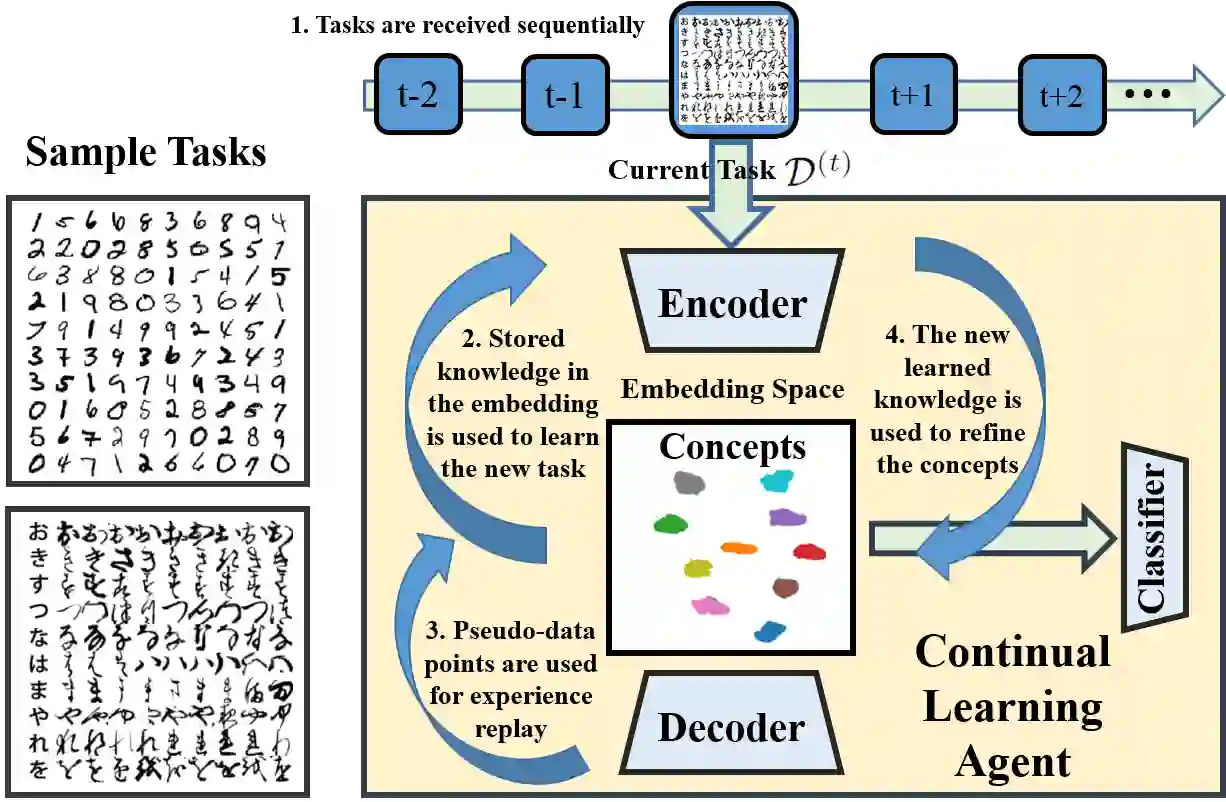
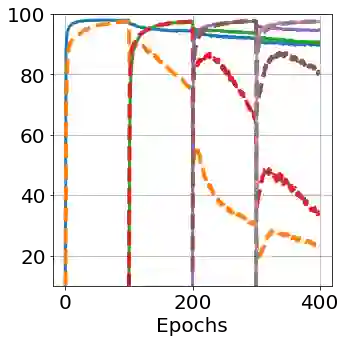
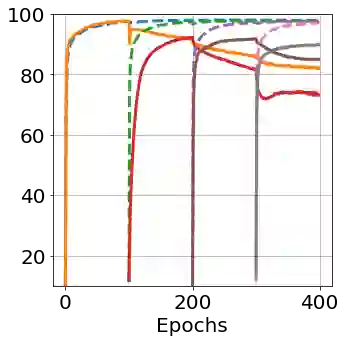
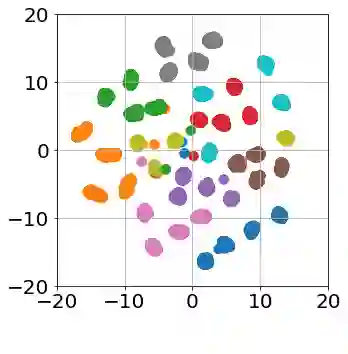
After learning a concept, humans are also able to continually generalize their learned concepts to new domains by observing only a few labeled instances without any interference with the past learned knowledge. In contrast, learning concepts efficiently in a continual learning setting remains an open challenge for current Artificial Intelligence algorithms as persistent model retraining is necessary. Inspired by the Parallel Distributed Processing learning and the Complementary Learning Systems theories, we develop a computational model that is able to expand its previously learned concepts efficiently to new domains using a few labeled samples. We couple the new form of a concept to its past learned forms in an embedding space for effective continual learning. Doing so, a generative distribution is learned such that it is shared across the tasks in the embedding space and models the abstract concepts. This procedure enables the model to generate pseudo-data points to replay the past experience to tackle catastrophic forgetting.
翻译:在学习一个概念后,人类还能够通过只观察几个标记的事例而不干扰过去学到的知识,不断将其学到的概念推广到新的领域。相反,在持续学习环境中,有效的学习概念仍然是当前人工智能算法的公开挑战,因为需要长期的模型再培训。在平行分布式处理学习和补充学习系统理论的启发下,我们开发了一个计算模型,能够利用少数标记的样本将其以前学到的概念有效地推广到新的领域。我们把新形式的概念与过去学习的形式结合起来,在嵌入空间中有效持续学习。我们这样做,一种基因化的分布学学到它能够贯穿在嵌入空间和模型的抽象概念中的任务中。这个程序使得模型能够生成假数据点,以重现过去的经验,解决灾难性的遗忘问题。
相关内容

Source: Apple - iOS 8


