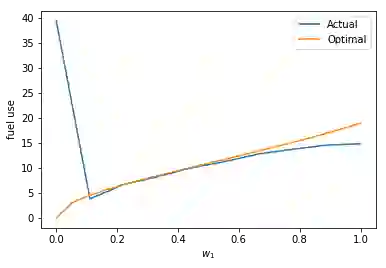
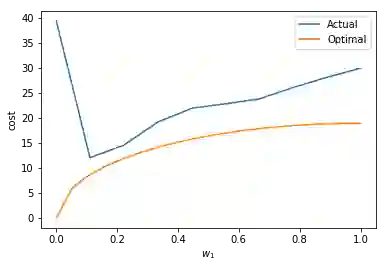
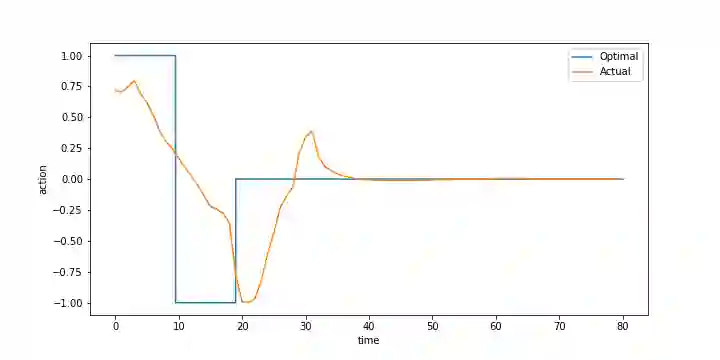
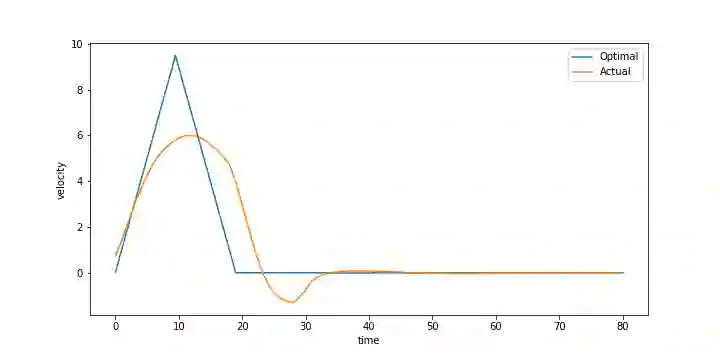
Many reinforcement-learning researchers treat the reward function as a part of the environment, meaning that the agent can only know the reward of a state if it encounters that state in a trial run. However, we argue that this is an unnecessary limitation and instead, the reward function should be provided to the learning algorithm. The advantage is that the algorithm can then use the reward function to check the reward for states that the agent hasn't even encountered yet. In addition, the algorithm can simultaneously learn policies for multiple reward functions. For each state, the algorithm would calculate the reward using each of the reward functions and add the rewards to its experience replay dataset. The Hindsight Experience Replay algorithm developed by Andrychowicz et al. (2017) does just this, and learns to generalize across a distribution of sparse, goal-based rewards. We extend this algorithm to linearly-weighted, multi-objective rewards and learn a single policy that can generalize across all linear combinations of the multi-objective reward. Whereas other multi-objective algorithms teach the Q-function to generalize across the reward weights, our algorithm enables the policy to generalize, and can thus be used with continuous actions.
翻译:许多强化学习研究人员将奖赏功能视为环境的一部分,这意味着代理人只有在遇到试验时才能知道一个国家的奖赏。 但是,我们争辩说,这是一个不必要的限制,而奖赏功能应该提供给学习算法。 其优点是, 算法可以使用奖赏功能来检查对代理人尚未遇到的国家的奖赏。 此外, 算法可以同时学习多种奖赏功能的政策。 对于每一个国家, 算法将使用每个奖赏功能计算奖赏, 并将奖赏添加到其经验重放数据集中。 由安德列克豪奇茨等人( 2017年) 开发的Hindsight Replay 算法就是这样做的, 并学会在分散的、 基于目标的奖赏分配中进行概括化。 我们把这个算法扩大到线性、 多重目标的奖赏, 并学习一种能够贯穿多目标奖赏的所有线性组合的单一政策。 而其他多目标的算法则教它如何在奖赏权重中进行概括化。 我们的算法可以使政策得以持续地使用。