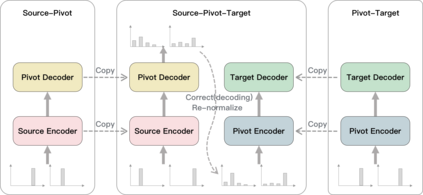
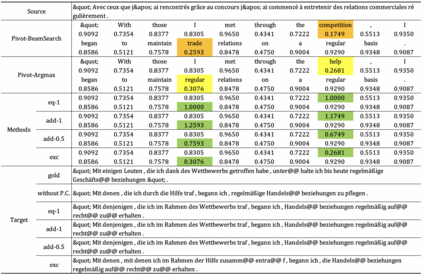
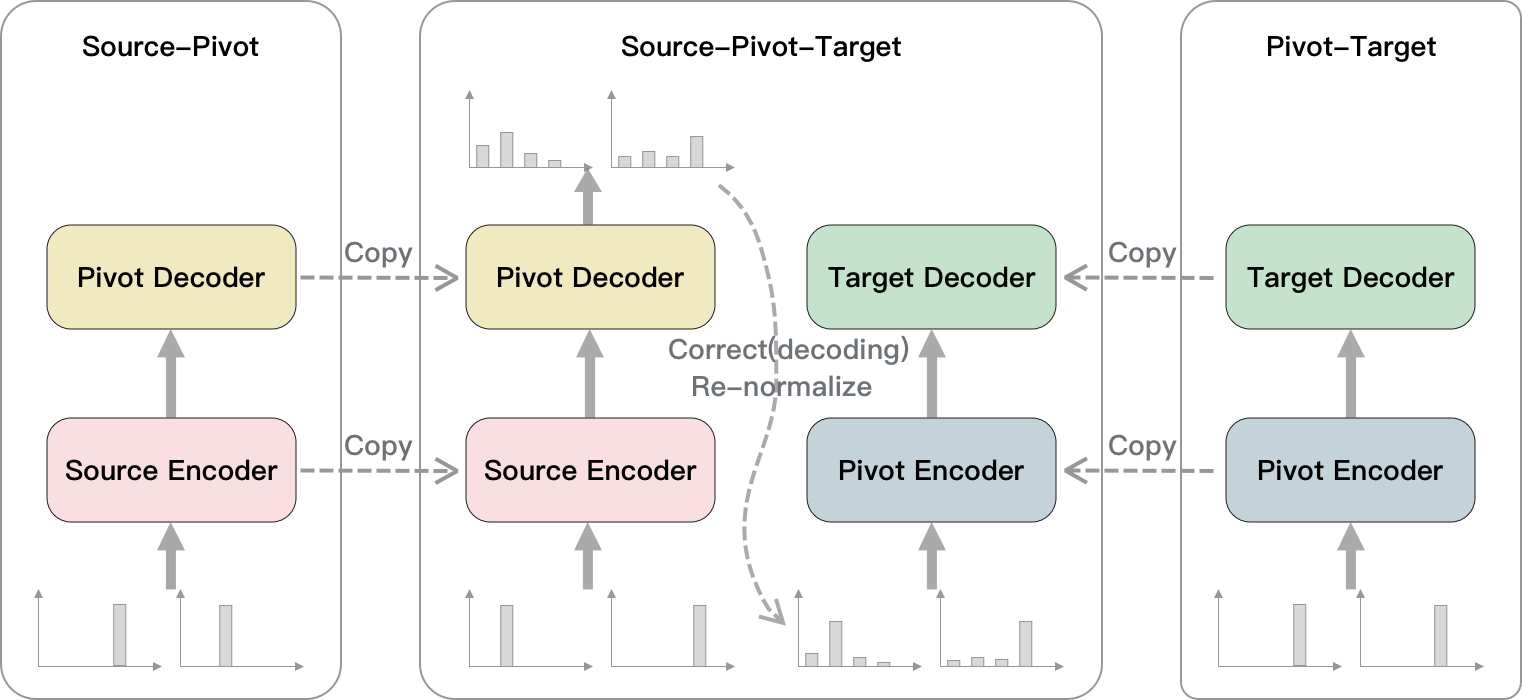
Utilizing pivot language effectively can significantly improve low-resource machine translation. Usually, the two translation models, source-pivot and pivot-target, are trained individually and do not utilize the limited (source, target) parallel data. This work proposes an end-to-end training method for the cascaded translation model and configures an improved decoding algorithm. The input of the pivot-target model is modified to weighted pivot embedding based on the probability distribution output by the source-pivot model. This allows the model to be trained end-to-end. In addition, we mitigate the inconsistency between tokens and probability distributions while using beam search in pivot decoding. Experiments demonstrate that our method enhances the quality of translation.
翻译:暂无翻译