
题目: Span-ConveRT: Few-shot Span Extraction for Dialog with Pretrained Conversational Representations
摘要:
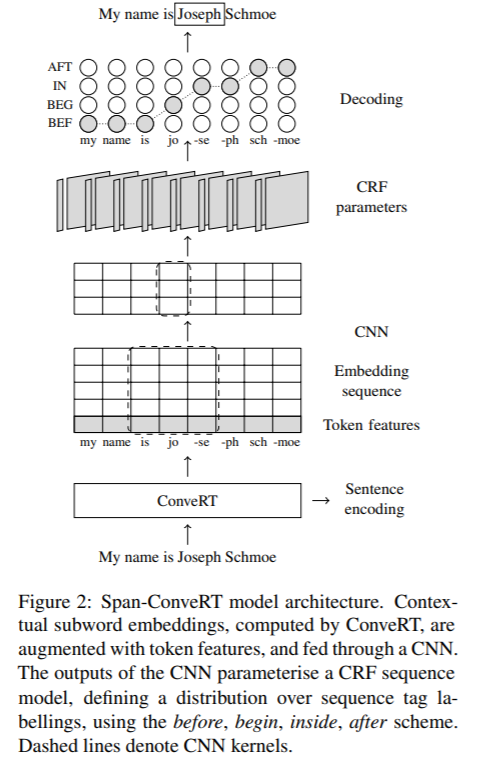
本文介绍了Span-ConveRT,这是一种用于对话框槽填充的轻量级模型,它将任务描述为基于轮的span提取任务。这个公式允许简单地集成编码在大型预先训练的会话模型中的会话知识,如ConveRT (Henderson等人,2019)。我们展示了在Span-ConveRT中利用这些知识对于很少的学习场景特别有用:
- 一个跨度提取器,在目标域从零开始训练表示,
- 基于bert的跨度提取器。
为了激发更多关于填槽任务的span提取的工作,我们还发布了RESTAURANTS-8K,这是一个新的具有挑战性的数据集,包含8,198个话语,是从餐馆预订领域的实际对话中汇编而成。
成为VIP会员查看完整内容
相关内容

专知会员服务
33+阅读 · 2020年2月29日
专知会员服务
32+阅读 · 2020年2月21日
专知会员服务
43+阅读 · 2020年1月28日
专知会员服务
52+阅读 · 2020年1月20日
Arxiv
5+阅读 · 2019年11月1日
Arxiv
7+阅读 · 2019年9月17日
相关主题
相关VIP内容
专知会员服务
33+阅读 · 2020年2月29日
专知会员服务
32+阅读 · 2020年2月21日
专知会员服务
43+阅读 · 2020年1月28日
专知会员服务
52+阅读 · 2020年1月20日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年11月1日
Arxiv
7+阅读 · 2019年9月17日