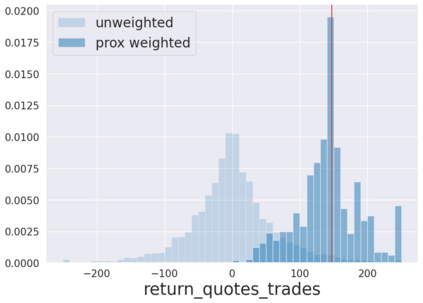
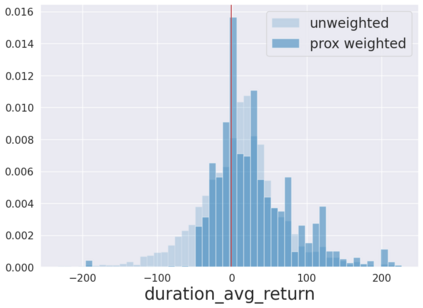
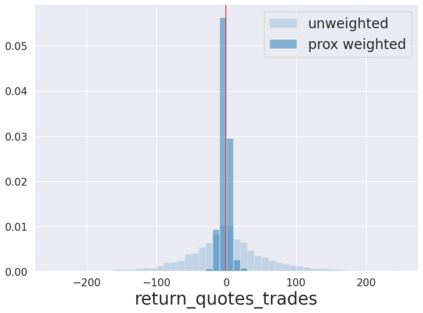
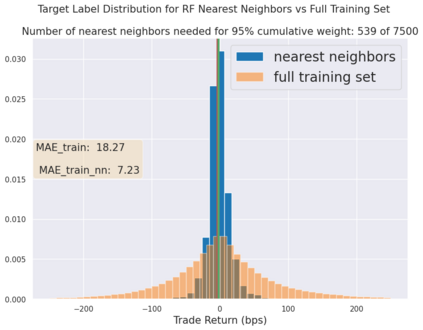
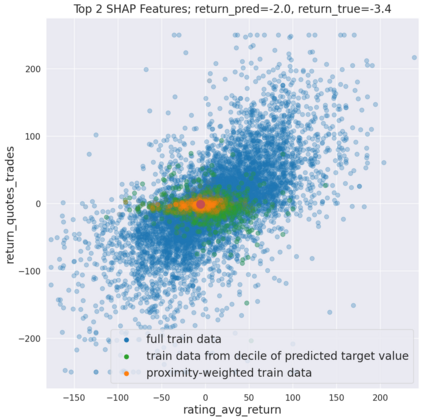
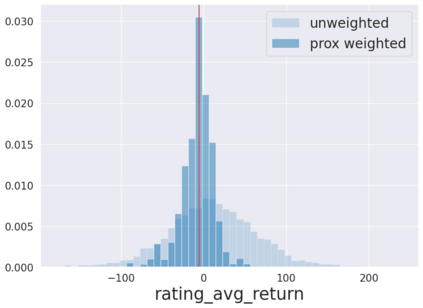
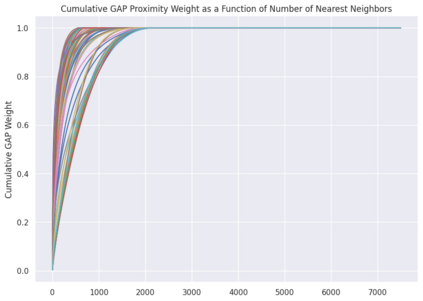
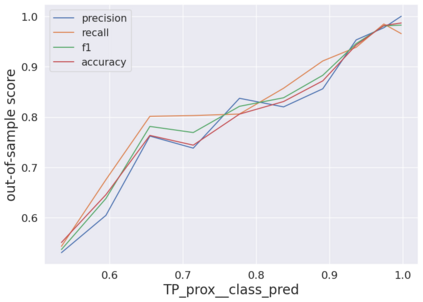
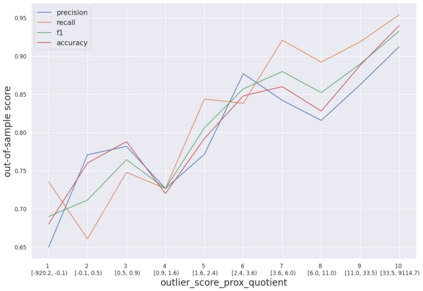
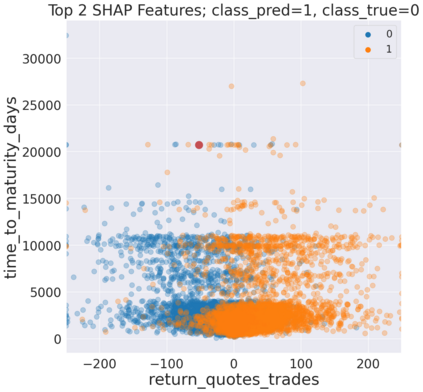
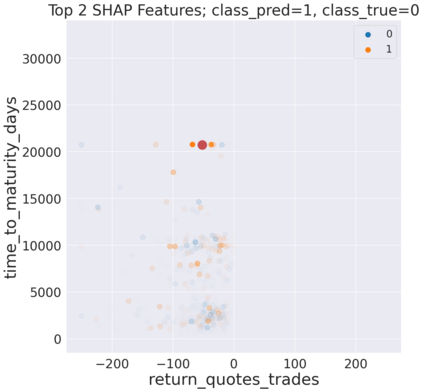
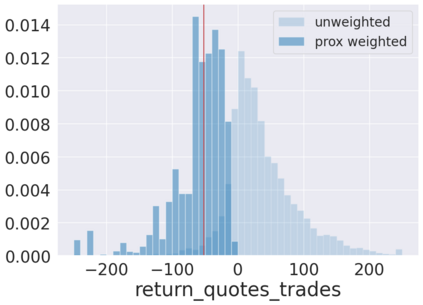
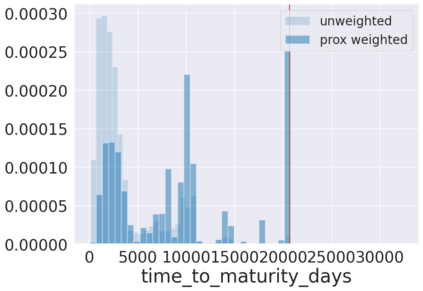
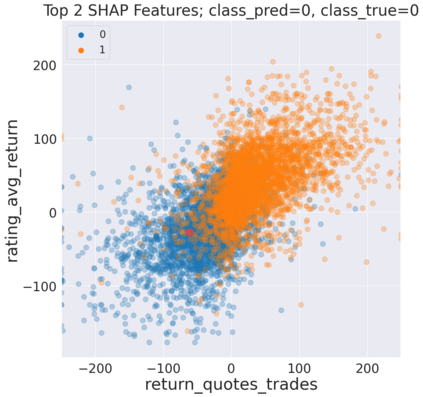
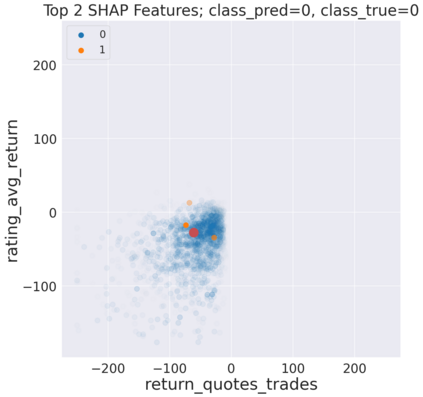
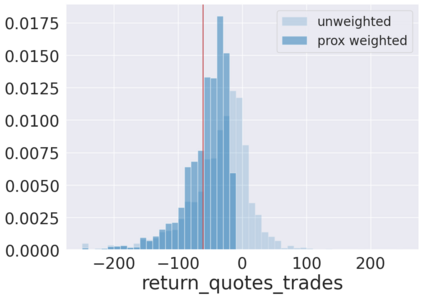
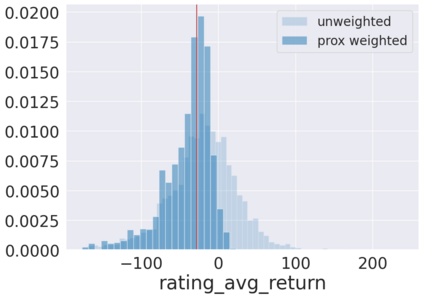
We initiate a novel approach to explain the predictions and out of sample performance of random forest (RF) regression and classification models by exploiting the fact that any RF can be mathematically formulated as an adaptive weighted K nearest-neighbors model. Specifically, we employ a recent result that, for both regression and classification tasks, any RF prediction can be rewritten exactly as a weighted sum of the training targets, where the weights are RF proximities between the corresponding pairs of data points. We show that this linearity facilitates a local notion of explainability of RF predictions that generates attributions for any model prediction across observations in the training set, and thereby complements established feature-based methods like SHAP, which generate attributions for a model prediction across input features. We show how this proximity-based approach to explainability can be used in conjunction with SHAP to explain not just the model predictions, but also out-of-sample performance, in the sense that proximities furnish a novel means of assessing when a given model prediction is more or less likely to be correct. We demonstrate this approach in the modeling of US corporate bond prices and returns in both regression and classification cases.
翻译:暂无翻译