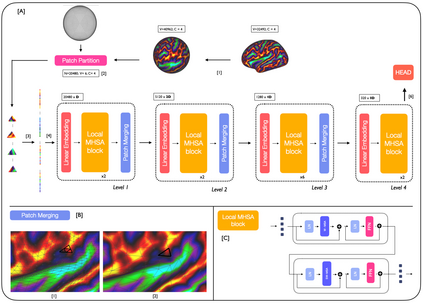
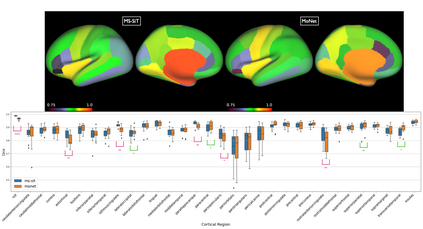
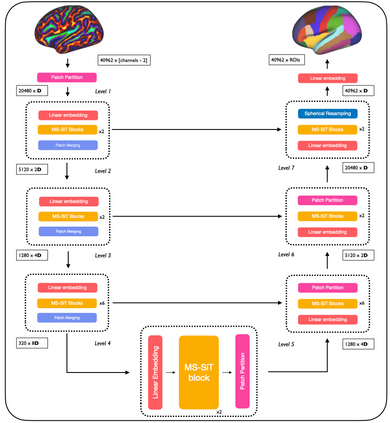
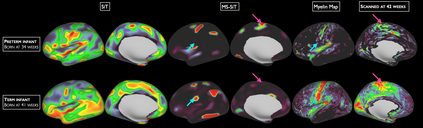
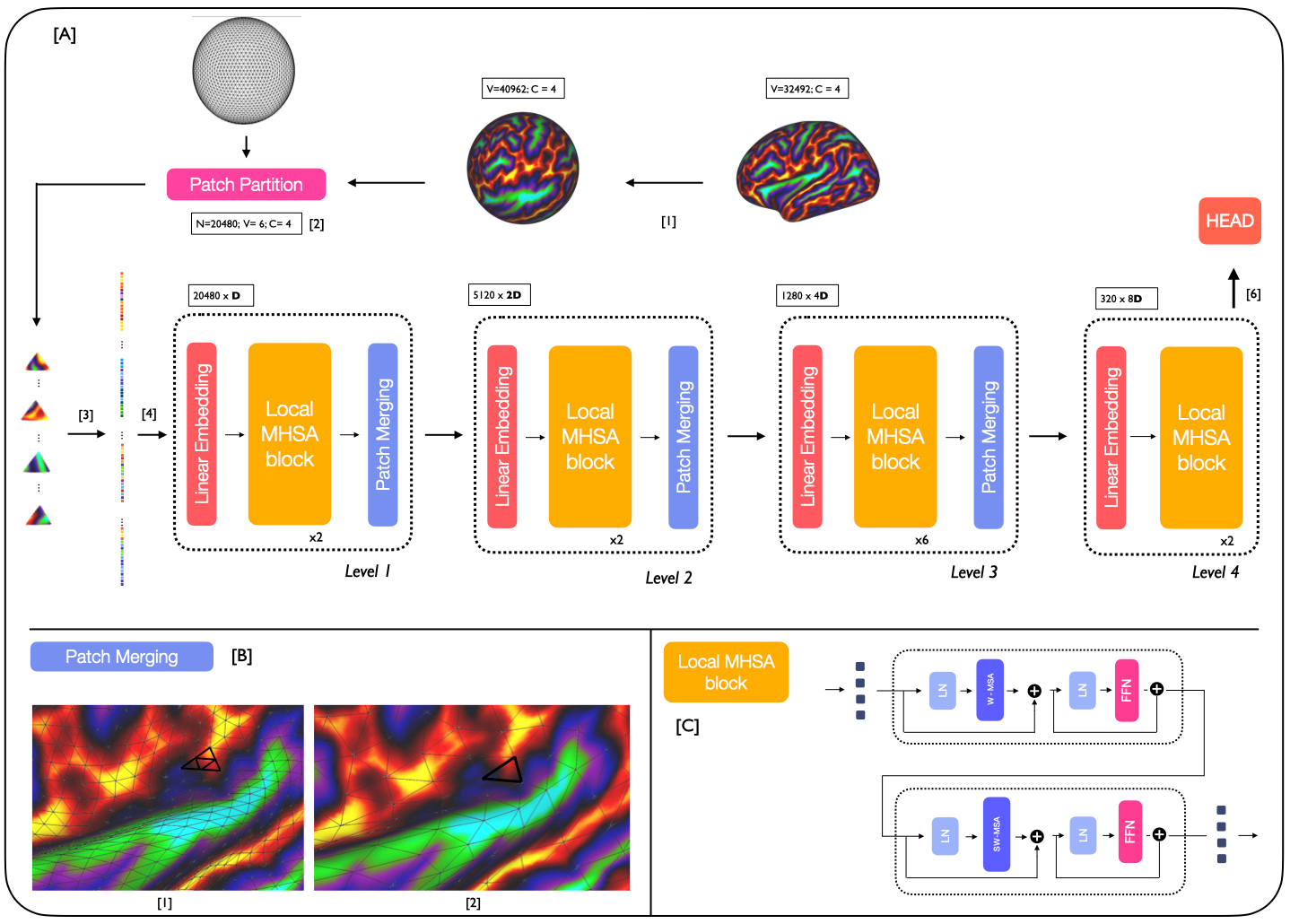
Surface meshes are a favoured domain for representing structural and functional information on the human cortex, but their complex topology and geometry pose significant challenges for deep learning analysis. While Transformers have excelled as domain-agnostic architectures for sequence-to-sequence learning, notably for structures where the translation of the convolution operation is non-trivial, the quadratic cost of the self-attention operation remains an obstacle for many dense prediction tasks. Inspired by some of the latest advances in hierarchical modelling with vision transformers, we introduce the Multiscale Surface Vision Transformer (MS-SiT) as a backbone architecture for surface deep learning. The self-attention mechanism is applied within local-mesh-windows to allow for high-resolution sampling of the underlying data, while a shifted-window strategy improves the sharing of information between windows. Neighbouring patches are successively merged, allowing the MS-SiT to learn hierarchical representations suitable for any prediction task. Results demonstrate that the MS-SiT outperforms existing surface deep learning methods for neonatal phenotyping prediction tasks using the Developing Human Connectome Project (dHCP) dataset. Furthermore, building the MS-SiT backbone into a U-shaped architecture for surface segmentation demonstrates competitive results on cortical parcellation using the UK Biobank (UKB) and manually-annotated MindBoggle datasets. Code and trained models are publicly available at https://github.com/metrics-lab/surface-vision-transformers .
翻译:表面网格是表示人类皮层结构和功能信息的优选领域,但其复杂的拓扑和几何形状对深度学习分析提出了重大挑战。虽然变形器在序列到序列学习方面表现出色,尤其是对于其中卷积操作的平移非平凡时,但自我注意操作的二次成本仍然是许多密集预测任务的障碍。受最新的多尺度模型化,带有视觉变换器的启发,我们引入了多尺度表面视觉变换器(MS-SiT)作为表面深度学习的骨干架构。自我注意机制应用于局部网格窗口中,以允许对底层数据进行高分辨率采样,而移位窗口策略则提高了窗口之间信息共享的效果。相邻的补丁被逐层合并,使得MS-SiT能够学习可适用于任何预测任务的分层表示。结果表明,使用发展中人类连接组学(dHCP)数据集对新生儿表型预测任务进行评估时,MS-SiT的表现优于现有的表面深度学习方法。此外,将MS-SiT骨干架构嵌入到用于表面分割的U型架构中,在UK Biobank (UKB)和手工注释的MindBoggle数据集上展现了竞争性的结果。代码和训练模型公开在 https://github.com/metrics-lab/surface-vision-transformers。