
目前基于多模态的人脸防伪算法存在两点不足:(1)基于多模态融合的方法要求提供与训练过程一致的模态样本,严重限制了算法的部署场景;(2)由于卷积操作挖掘视觉线索的挑战,基于ConvNet的模型对新出现的高保真攻击样本表现不佳。在本文工作中,我们提出了一基于纯Transformer的框架,称为灵活模态的Transformer(FM-ViT),用于人脸防伪任务,以借助多模态信息灵活地提升对任何单一模态攻击的识别性能。为了实现该目的,FM-ViT首先为每种模态保留一个特定的分支,以学习不同的模态信息。同时引入跨模态Transformer块(CMTB),由两个级联的注意力模块组成,分别称为Multi-headed Mutual-Attention(MMA)和Fusion-Attention(MFA),分别用于引导每个分支学习潜在的和模态无关的活性特征。
具体来说,如图1(a)所示,FM-ViT建立在多个ViT分支上,由token化模块、Transformer编码器和分类头组成。一个完整的Transformer编码器包含K个“阶段”。其中每个“阶段”由M个标准Transformer块(STB)和一个跨模态Transformer块(CMTB)堆叠。在每个“阶段”中,CMTB共享权值(用红色双箭头线显示),并接收之前多模态STBs的输出作为输入(用虚线显示)。如图1(b)所示,CMTB由两个级联的MMA和MFA组成。STBs与CMTB构成Transformer编码器的一个“阶段”。如图1(c)所示,MMA计算所有模态的相关图,以挖掘任意模态分支中潜在patch tokens;MFA为任意模态分支融合其他分支的模态信息,指导当前分支学习模态无关的活性特征。
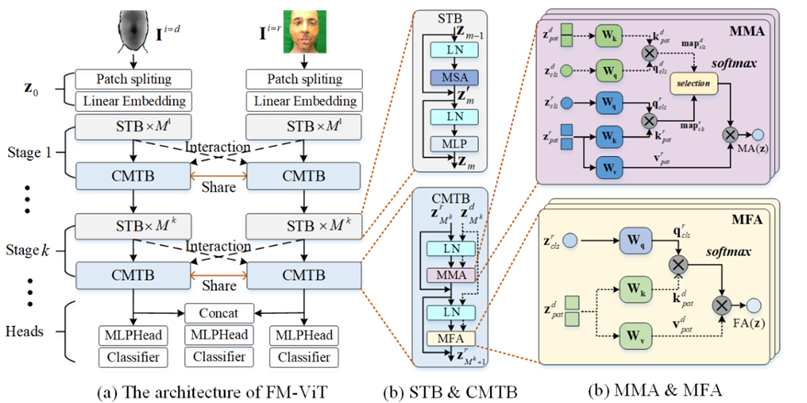
图. 一种基于灵活模态的人脸防伪方法示意图
作者:Ajian Liu, Zichang Tan, Jun Wan, Yanyan Liang, Zhen Lei, Guodong Guo, Stan Z. Li




