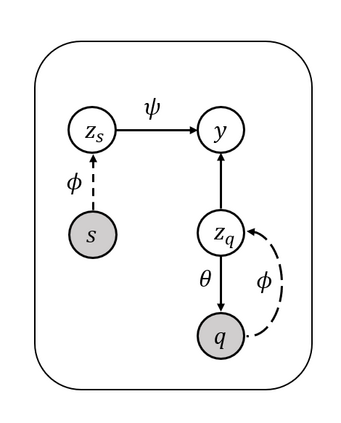
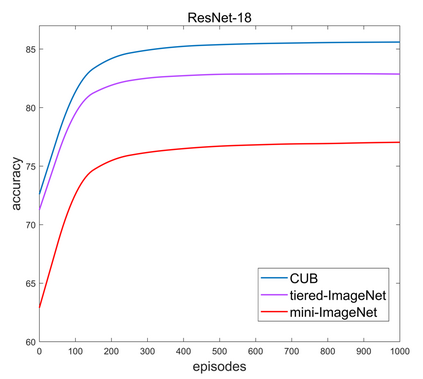
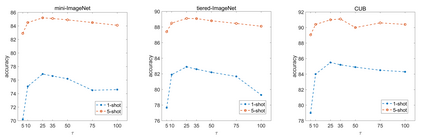
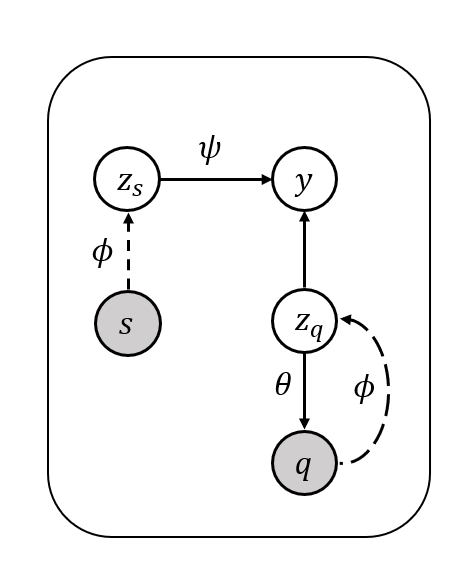
Transductive methods always outperform inductive methods in few-shot image classification scenarios. However, the existing few-shot methods contain a latent condition: the number of samples in each class is the same, which may be unrealistic. To cope with those cases where the query shots of each class are nonuniform (i.e. nonuniform few-shot learning), we propose a Task-Prior Conditional Variational Auto-Encoder model named TP-VAE, conditioned on support shots and constrained by a task-level prior regularization. Our method obtains high performance in the more challenging nonuniform few-shot scenarios. Moreover, our method outperforms the state-of-the-art in a wide range of standard few-shot image classification scenarios. Among them, the accuracy of 1-shot increased by about 3\%.
翻译:转基因方法总是优于在几发图像分类假设情景中的感应方法。然而,现有的微粒方法含有潜在条件:每类样本的数量相同,可能不切实际。为了应对每类的查询镜头不统一(即不统一微粒学习)的情况,我们建议采用名为TP-VAE的特遣-初级条件变异自动-Encoder模型,该模型以支持射击为条件,并受任务级别先前的规范制约。我们的方法在更具挑战性的非统一微粒假设中取得了很高的性能。此外,我们的方法在一系列标准的几发图像分类假设中超过了最新水平。其中,1发的精确度增加了约3 ⁇ 。