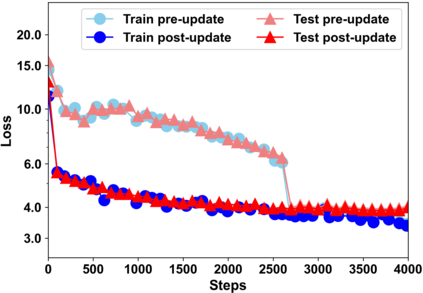
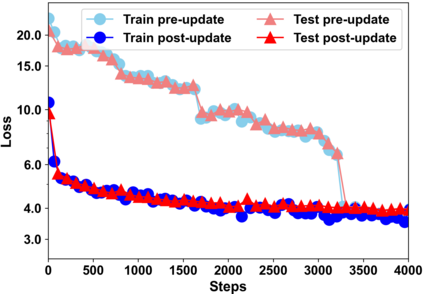
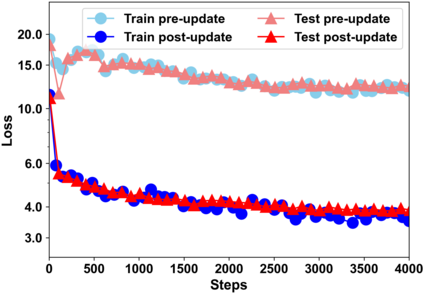
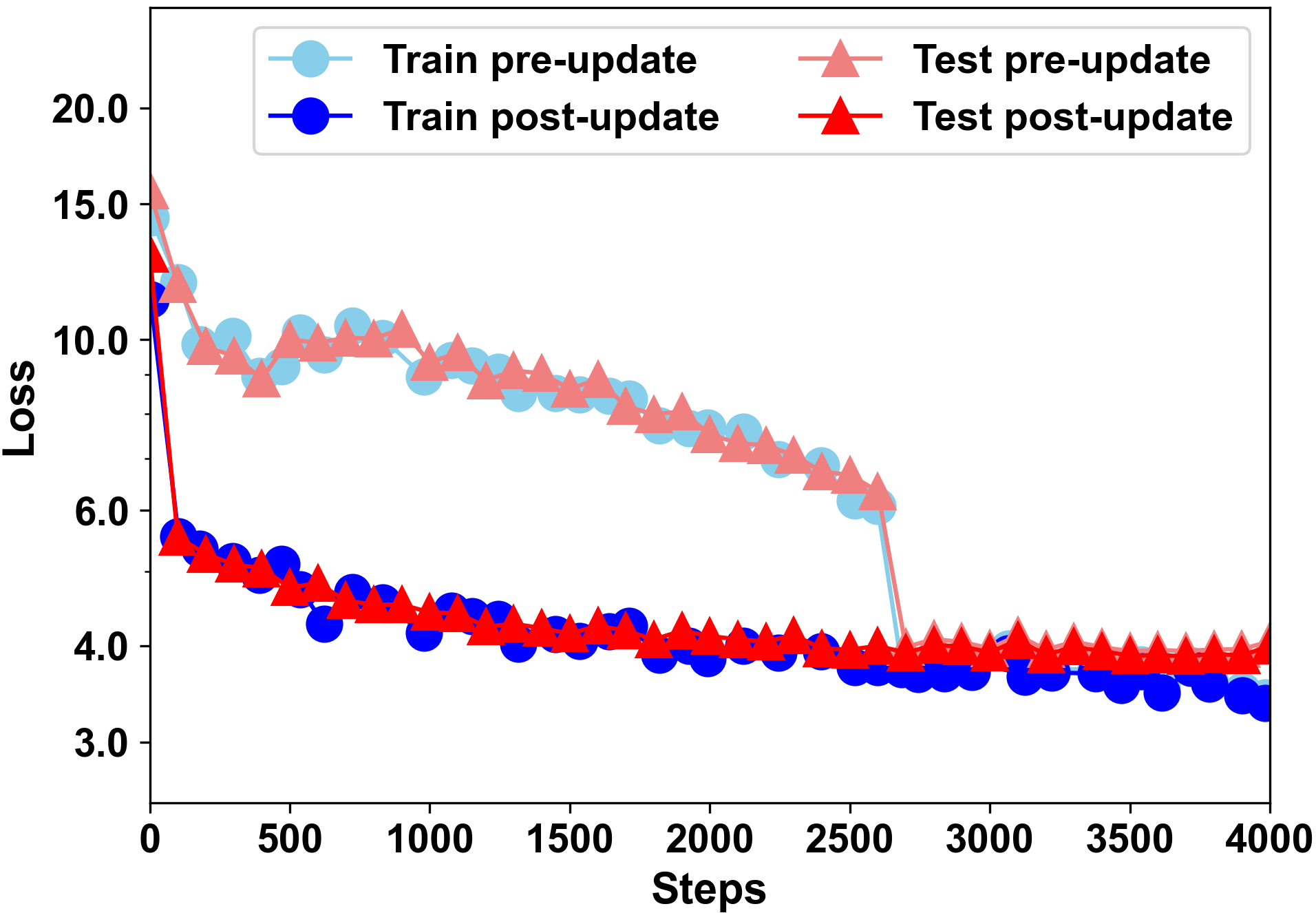
Building models of natural language processing (NLP) is challenging in low-resource scenarios where only limited data are available. Optimization-based meta-learning algorithms achieve promising results in low-resource scenarios by adapting a well-generalized model initialization to handle new tasks. Nonetheless, these approaches suffer from the memorization overfitting issue, where the model tends to memorize the meta-training tasks while ignoring support sets when adapting to new tasks. To address this issue, we propose a memory imitation meta-learning (MemIML) method that enhances the model's reliance on support sets for task adaptation. Specifically, we introduce a task-specific memory module to store support set information and construct an imitation module to force query sets to imitate the behaviors of some representative support-set samples stored in the memory. A theoretical analysis is provided to prove the effectiveness of our method, and empirical results also demonstrate that our method outperforms competitive baselines on both text classification and generation tasks.
翻译:在仅具备有限数据的低资源情景下,建设自然语言处理模型(NLP)具有挑战性。优化的元学习算法在低资源情景下取得了大有希望的成果,通过调整一个非常通用的模型初始化来应对新任务。然而,这些方法却受到超称的记忆化问题的影响,模型往往在适应新任务时将元培训任务混为一文,而忽略了支助组。为了解决这一问题,我们建议采用记忆模拟元学习方法,加强模型对任务适应支持组的依赖。具体地说,我们引入一个任务特定的记忆模块,用于储存已安装的信息,并构建一个模拟模块,以强制查询组模仿存储在记忆中的一些有代表性的支持设置样本的行为。提供了理论分析,以证明我们的方法的有效性,经验结果还表明,我们的方法在文本分类和生成任务上都超越了竞争性基线。