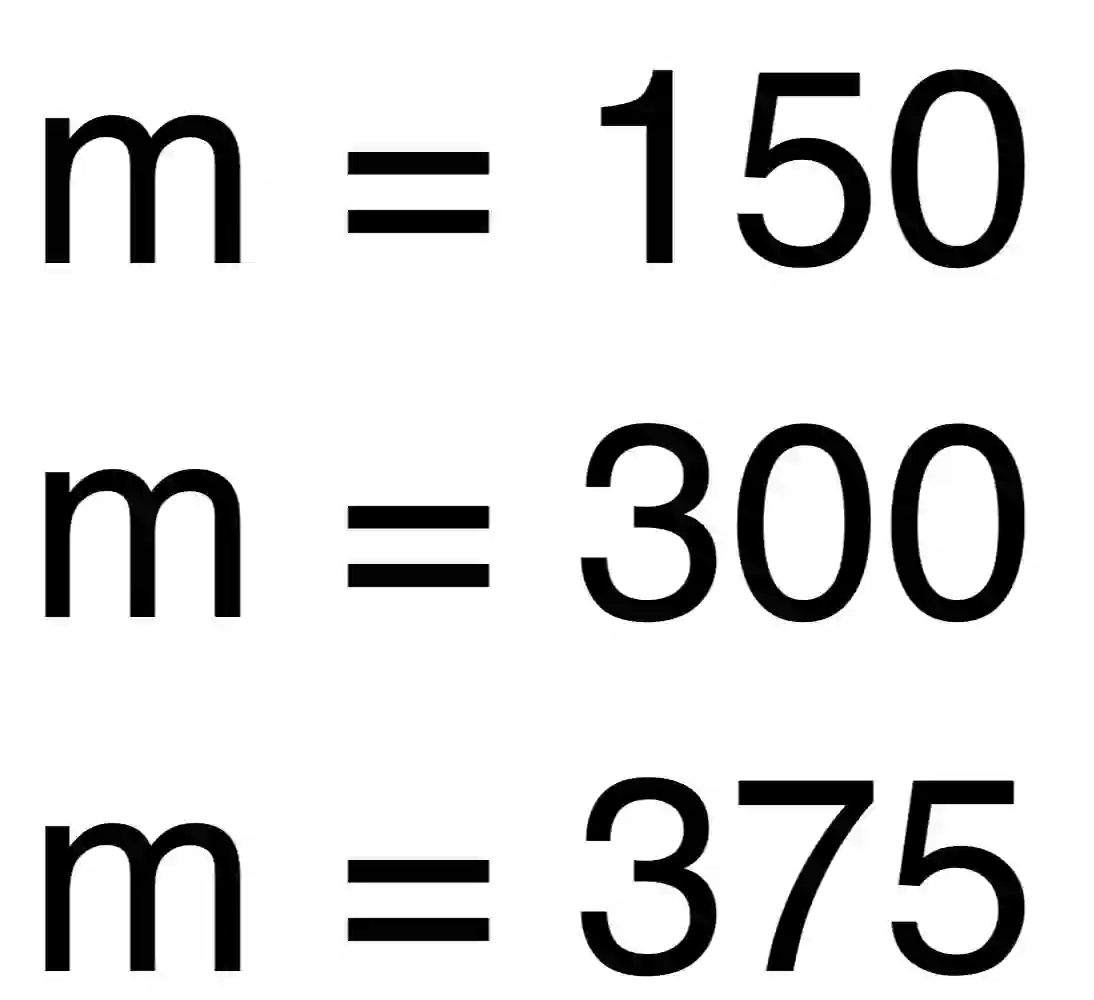Group testing can help maintain a widespread testing program using fewer resources amid a pandemic. In a group testing setup, we are given n samples, one per individual. Each individual is either infected or uninfected. These samples are arranged into m < n pooled samples, where each pool is obtained by mixing a subset of the n individual samples. Infected individuals are then identified using a group testing algorithm. In this paper, we incorporate side information (SI) collected from contact tracing (CT) into nonadaptive/single-stage group testing algorithms. We generate different types of possible CT SI data by incorporating different possible characteristics of the spread of the disease. These data are fed into a group testing framework based on generalized approximate message passing (GAMP). Numerical results show that our GAMP-based algorithms provide improved accuracy. Compared to a loopy belief propagation algorithm, our proposed framework can increase the success probability by 0.25 for a group testing problem of n = 500 individuals with m = 100 pooled samples.
翻译:群体测试有助于在大流行病中利用较少的资源维持一个广泛的测试程序。在集体测试中,我们得到的是每个人一份的样本。每个人要么是感染者,要么是未感染者。这些样本被安排在m < n 集合样本中,每个集合样本是通过混合一个子集的单个样本获得的。然后通过群体测试算法确定感染者的身份。在本文中,我们将从接触跟踪(CT)收集的侧面信息纳入非适应性/单阶段群体测试算法中。我们通过纳入疾病传播的不同可能特征,生成了不同类型的CT SI数据。这些数据被输入一个基于通用近似信息(GAMP)的团体测试框架。数字结果显示,我们基于 GAMMP的算法提供了更好的准确性。与循环信仰传播算法相比,我们提议的框架可以增加0.25的成功的概率,因为一个群体测试问题为n=500人,其中M=100个集合样本。