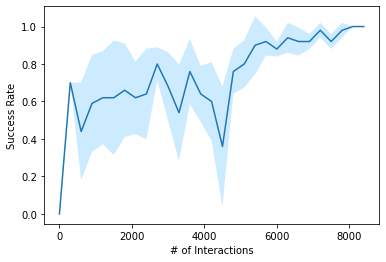
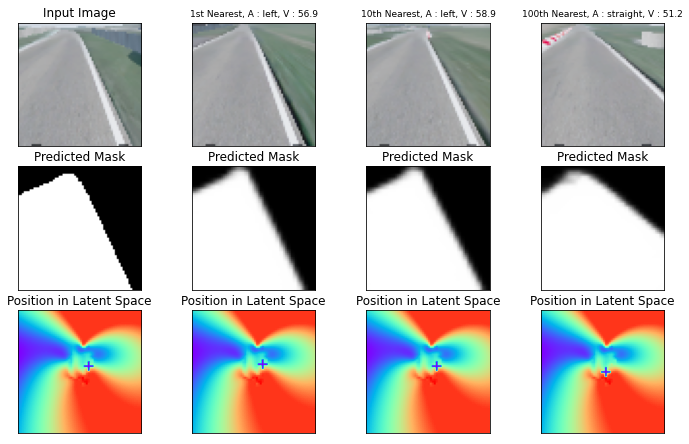
The practical application of learning agents requires sample efficient and interpretable algorithms. Learning from behavioral priors is a promising way to bootstrap agents with a better-than-random exploration policy or a safe-guard against the pitfalls of early learning. Existing solutions for imitation learning require a large number of expert demonstrations and rely on hard-to-interpret learning methods like Deep Q-learning. In this work we present a planning-based approach that can use these behavioral priors for effective exploration and learning in a reinforcement learning environment, and we demonstrate that curated exploration policies in the form of behavioral priors can help an agent learn faster.
翻译:学习代理人的实际应用需要抽样、高效和可解释的算法。从行为前科中学习是一种很有希望的方法,可以让行为前科者掌握更好的探索政策或防止早期学习的陷阱。现有的模仿学习解决方案需要大量的专家演示,并依靠深Q学习等难以解释的学习方法。在这项工作中,我们提出了一个基于规划的方法,可以利用这些行为前科在强化学习环境中进行有效的探索和学习,我们证明,以行为前科形式制定的探索政策可以帮助代理人更快地学习。