
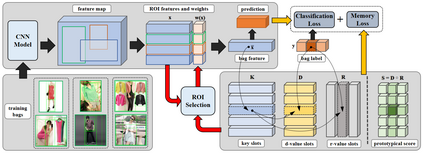
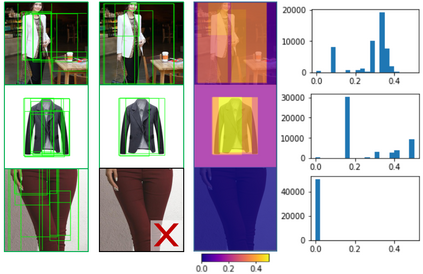
Learning from web data has attracted lots of research interest in recent years. However, crawled web images usually have two types of noises, label noise and background noise, which induce extra difficulties in utilizing them effectively. Most existing methods either rely on human supervision or ignore the background noise. In this paper, we propose a novel method, which is capable of handling these two types of noises together, without the supervision of clean images in the training stage. Particularly, we formulate our method under the framework of multi-instance learning by grouping ROIs (i.e., images and their region proposals) from the same category into bags. ROIs in each bag are assigned with different weights based on the representative/discriminative scores of their nearest clusters, in which the clusters and their scores are obtained via our designed memory module. Our memory module could be naturally integrated with the classification module, leading to an end-to-end trainable system. Extensive experiments on four benchmark datasets demonstrate the effectiveness of our method.
翻译:近年来,从网络数据中学习,引起了许多研究兴趣。然而,爬行的网络图像通常有两种类型的噪音、标签噪音和背景噪音,这在有效利用它们方面引起额外的困难。大多数现有方法要么依靠人的监督,要么忽视背景噪音。在本文中,我们提出了一个新颖的方法,它能够同时处理这两类噪音,而无需在培训阶段对清洁图像进行监督。特别是,我们通过将同一类别中的ROIs(即图像及其区域建议)分组成袋,在多份学习的框架内制定我们的方法。每个包中的ROI根据它们最近的组群的代表性/差异性分数分配不同重量,通过我们设计的记忆模块获得这些组及其分数。我们的记忆模块可以自然地与分类模块结合,导致一个端到端的可培训系统。对四个基准数据集进行广泛的实验,显示了我们的方法的有效性。



相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

