
主题: Learning Term Discrimination
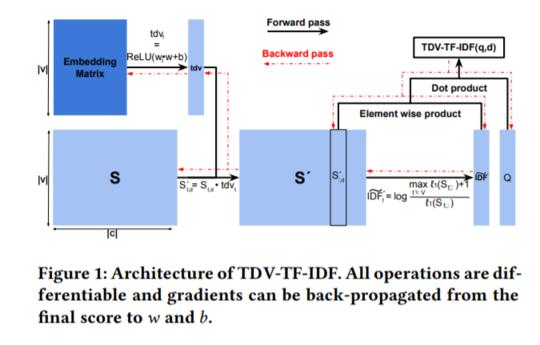
摘要: 文档索引是有效信息检索(IR)的关键组件。经过诸如词干和停用词删除之类的预处理步骤之后,文档索引通常会存储term-frequencies(tf)。与tf(仅反映一个术语在文档中的重要性)一起,传统的IR模型使用诸如反文档频率(idf)之类的术语区分值(TDV)在检索过程中偏向于区分性术语。在这项工作中,我们建议使用浅层神经网络学习TDV,以进行文档索引,该浅层神经网络可以近似TF-IDF和BM25等传统的IR排名功能。我们的建议在nDCG和召回方面均优于传统方法,即使很少有带有正标签的查询文档对作为学习数据。我们学到的TDV用于过滤区分度为零的词汇,不仅可以显着降低倒排索引的内存占用量,而且可以加快检索过程(BM25的速度提高了3倍),而不会降低检索质量。
成为VIP会员查看完整内容
相关内容



相关VIP内容
相关资讯
相关论文