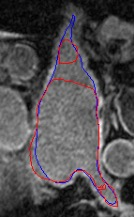
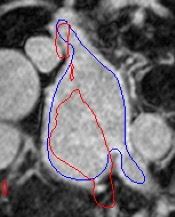
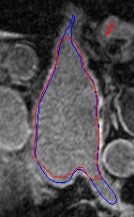
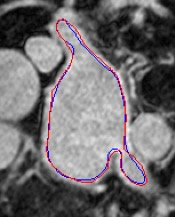
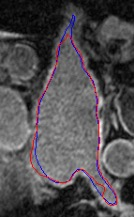
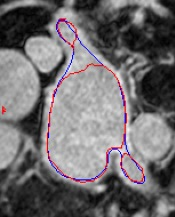
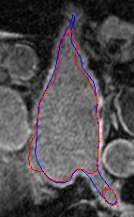
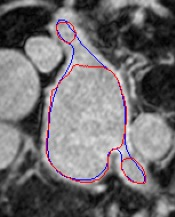
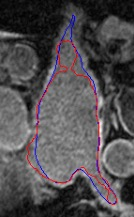
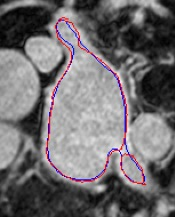
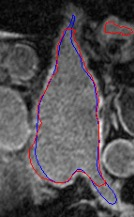
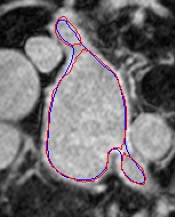
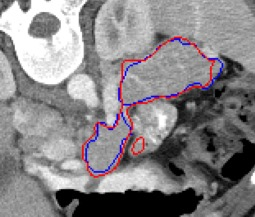
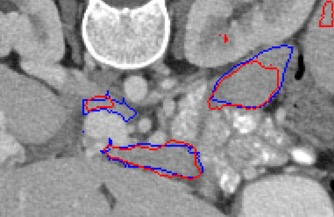
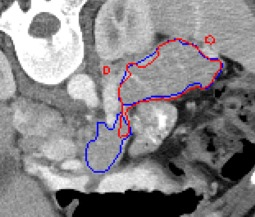
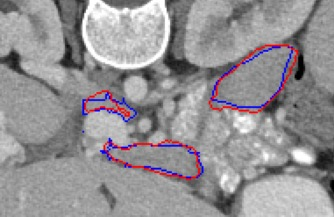
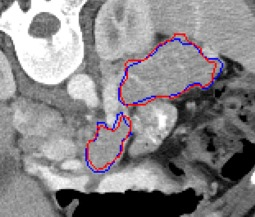
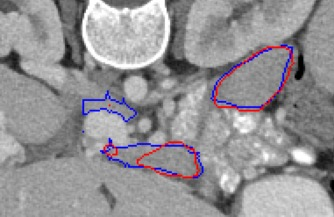
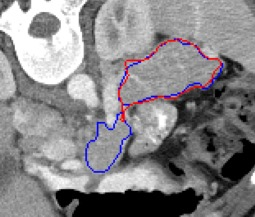
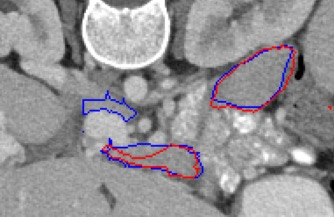
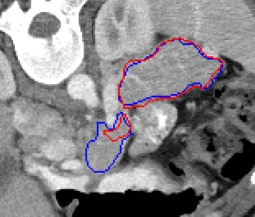
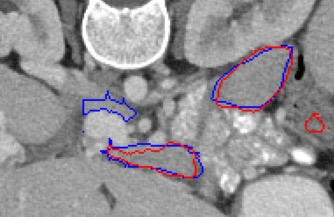
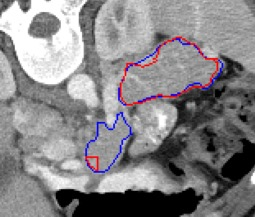
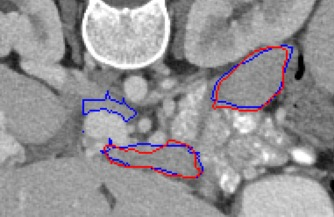
Automated segmentation in medical image analysis is a challenging task that requires a large amount of manually labeled data. However, most existing learning-based approaches usually suffer from limited manually annotated medical data, which poses a major practical problem for accurate and robust medical image segmentation. In addition, most existing semi-supervised approaches are usually not robust compared with the supervised counterparts, and also lack explicit modeling of geometric structure and semantic information, both of which limit the segmentation accuracy. In this work, we present SimCVD, a simple contrastive distillation framework that significantly advances state-of-the-art voxel-wise representation learning. We first describe an unsupervised training strategy, which takes two views of an input volume and predicts their signed distance maps of object boundaries in a contrastive objective, with only two independent dropout as mask. This simple approach works surprisingly well, performing on the same level as previous fully supervised methods with much less labeled data. We hypothesize that dropout can be viewed as a minimal form of data augmentation and makes the network robust to representation collapse. Then, we propose to perform structural distillation by distilling pair-wise similarities. We evaluate SimCVD on two popular datasets: the Left Atrial Segmentation Challenge (LA) and the NIH pancreas CT dataset. The results on the LA dataset demonstrate that, in two types of labeled ratios (i.e., 20% and 10%), SimCVD achieves an average Dice score of 90.85% and 89.03% respectively, a 0.91% and 2.22% improvement compared to previous best results. Our method can be trained in an end-to-end fashion, showing the promise of utilizing SimCVD as a general framework for downstream tasks, such as medical image synthesis and registration.
翻译:医学图像分析中的自动分割是一个具有挑战性的任务,需要大量的手工标签数据。然而,大多数基于学习的现有方法通常都因有限的手工附加附加说明的医疗数据而受到影响,这对准确和稳健的医疗图像分割构成重大的实际问题。此外,大多数现有的半监督方法通常与受监督的对应方相比并不健全,而且缺乏明确的几何结构和语义信息的建模,两者都限制了分割的准确性。在这项工作中,我们提出了SimCVD,一个简单的对比性蒸馏框架,大大推进了最先进的Voxel-witter代表制演示学习。我们首先描述了一个未经超前的训练战略,该战略对一个输入量提出了两种观点,并预测了它们签字的天体界限的距离图,只有两个独立的弃置面罩。这一简单的方法运作得令人惊讶,在与以往完全监督的方法相同的水平上,用较少标签的数据。我们假设,可以将辍学视为数据增强的最小形式,并使网络更加稳健。然后,我们提议用SIM-D平均数据格式进行结构的对比,将SIM-L数据转换为我们之前的排序数据输入结果。