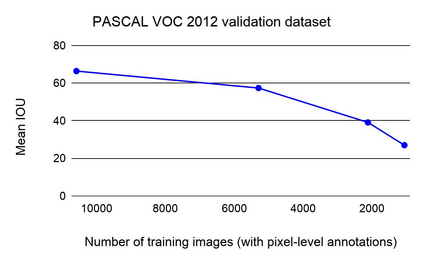
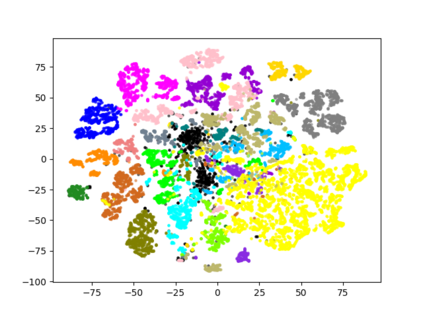
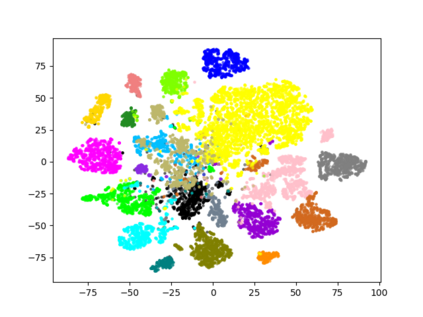
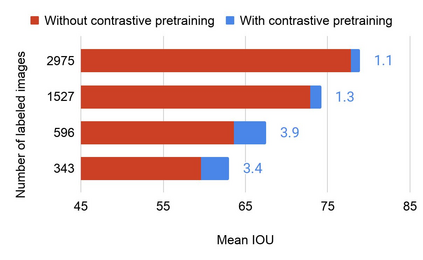
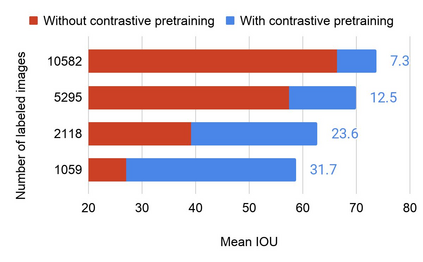
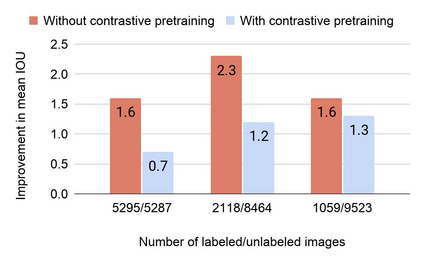
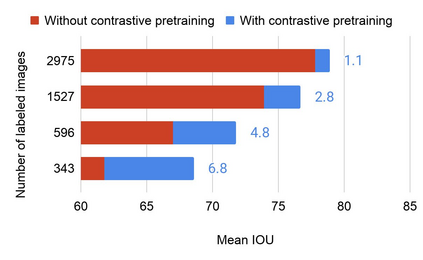
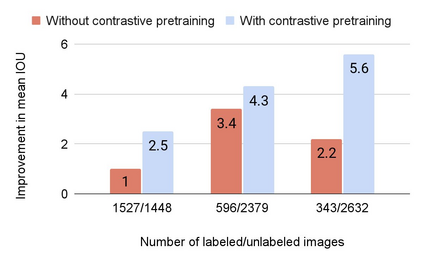
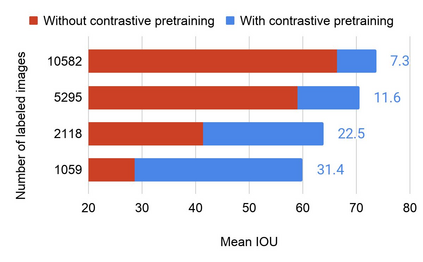
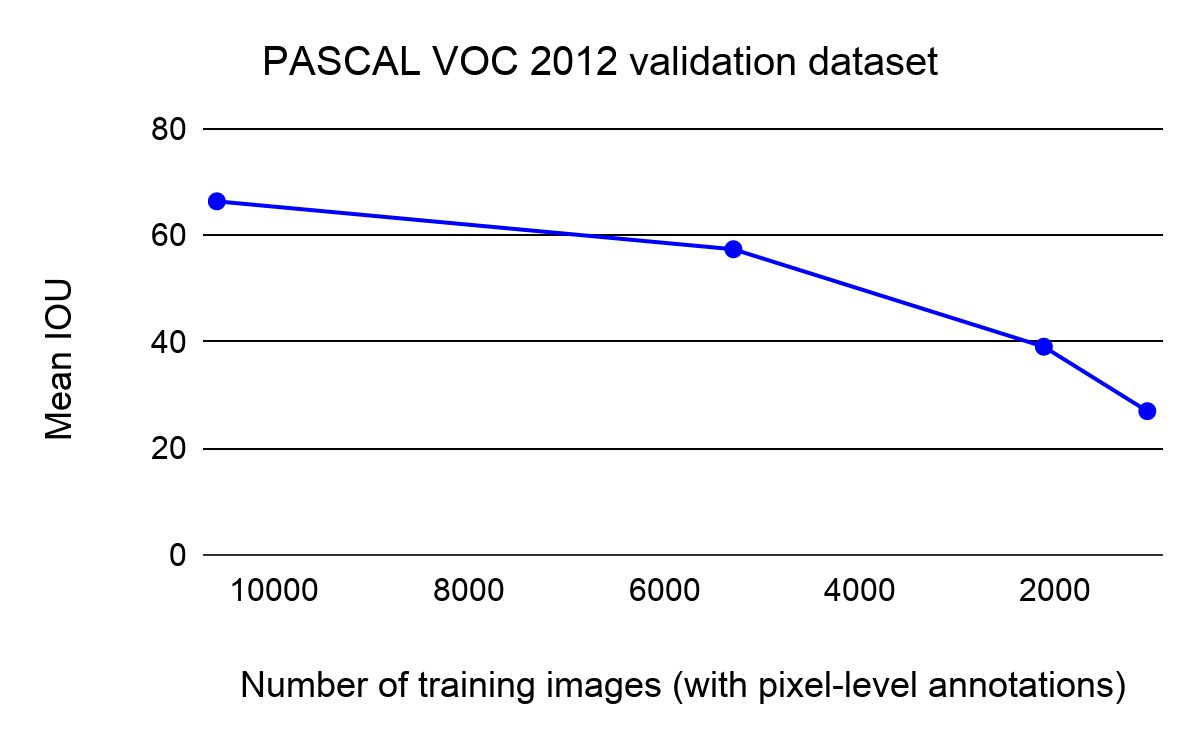
Collecting labeled data for the task of semantic segmentation is expensive and time-consuming, as it requires dense pixel-level annotations. While recent Convolutional Neural Network (CNN) based semantic segmentation approaches have achieved impressive results by using large amounts of labeled training data, their performance drops significantly as the amount of labeled data decreases. This happens because deep CNNs trained with the de facto cross-entropy loss can easily overfit to small amounts of labeled data. To address this issue, we propose a simple and effective contrastive learning-based training strategy in which we first pretrain the network using a pixel-wise class label-based contrastive loss, and then fine-tune it using the cross-entropy loss. This approach increases intra-class compactness and inter-class separability thereby resulting in a better pixel classifier. We demonstrate the effectiveness of the proposed training strategy in both fully-supervised and semi-supervised settings using the Cityscapes and PASCAL VOC 2012 segmentation datasets. Our results show that pretraining with label-based contrastive loss results in large performance gains (more than 20% absolute improvement in some settings) when the amount of labeled data is limited.
翻译:收集用于静脉分解任务的标签数据既昂贵又费时,因为这需要密集的像素级说明。虽然最近以进化神经网络(CNN)为基础的静脉分解方法通过使用大量标签培训数据取得了令人印象深刻的成果,但随着标签数据减少,其性能却显著下降。这是因为深重的CNN在事实上交叉机能损失方面受过培训的跨脑机能损失可以很容易地超过少量的标签数据。为了解决这一问题,我们提出了一个简单而有效的对比性学习培训战略,我们首先使用像素类标签类对比性损失来预设网络,然后使用交叉机能损失来微调网络。这一方法提高了等级内部的紧凑性和阶级间分离性,从而导致更好的像素分解器。我们用市景和PASCAL VOC2012分解数据设置来展示了拟议的培训战略的有效性。我们的结果显示,在基于标签的绝对数据损益度上,在基于标签的绝对损益度上,有一定比例的改进是20的。