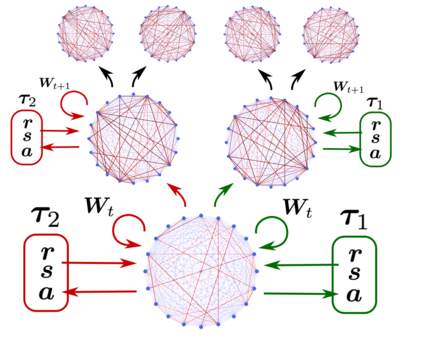
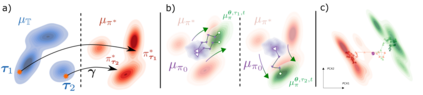
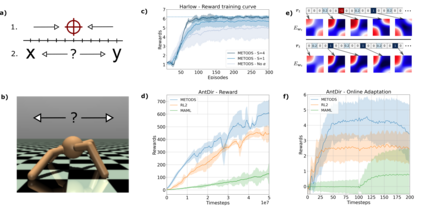
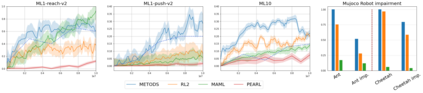
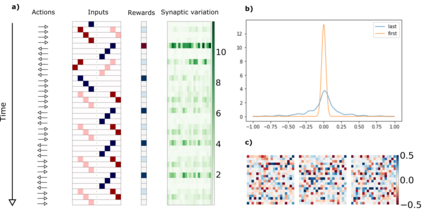
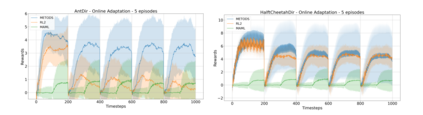
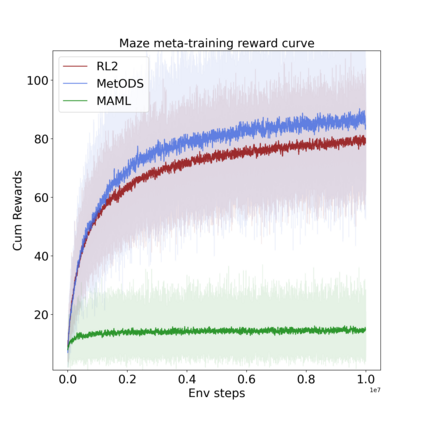
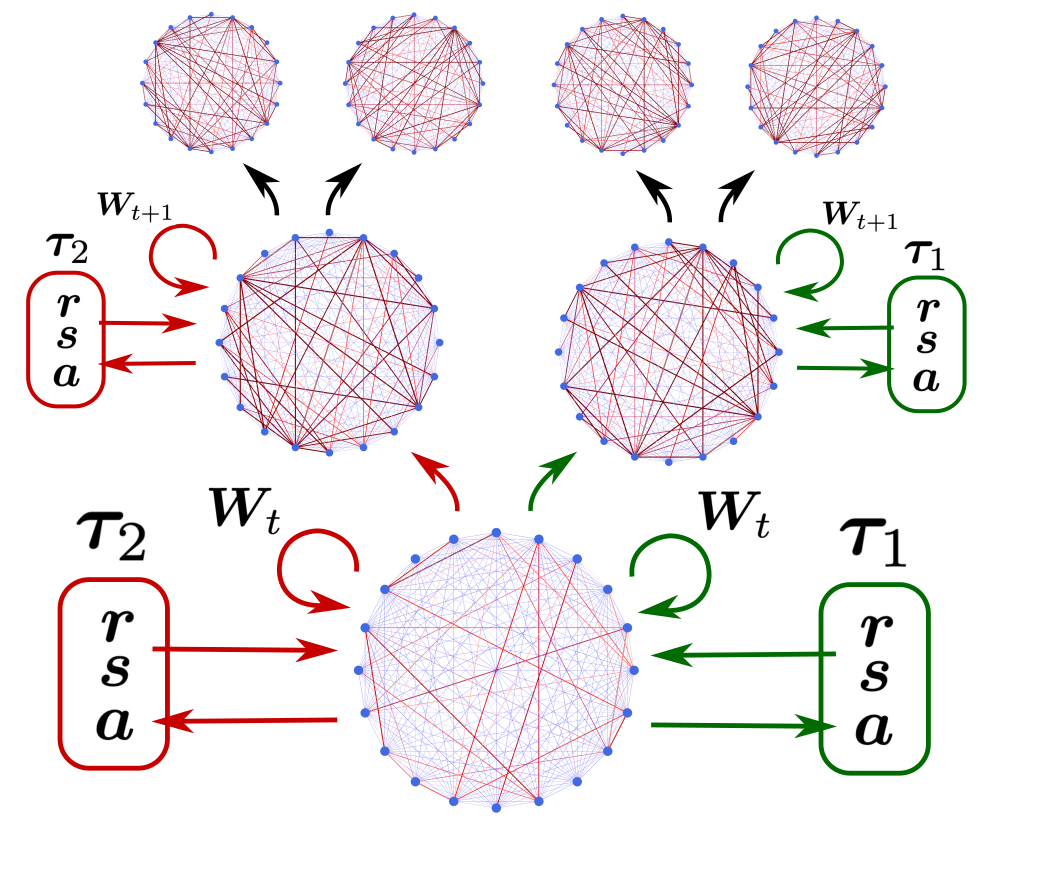
Deep Reinforcement Learning has demonstrated the potential of neural networks tuned with gradient descent for solving complex tasks in well-delimited environments. However, these neural systems are slow learners producing specialised agents with no mechanism to continue learning beyond their training curriculum. On the contrary, biological synaptic plasticity is persistent and manifold, and has been hypothesised to play a key role in executive functions such as working memory and cognitive flexibility, potentially supporting more efficient and generic learning abilities. Inspired by this, we propose to build networks with dynamic weights, able to continually perform self-reflexive modification as a function of their current synaptic state and action-reward feedback, rather than a fixed network configuration. The resulting model, MetODS (for Meta-Optimized Dynamical Synapses) is a broadly applicable meta-reinforcement learning system able to learn efficient and powerful control rules in the agent policy space. A single layer with dynamic synapses can perform one-shot learning, generalize navigation principles to unseen environments and demonstrate a strong ability to learn adaptive motor policies, comparing favourably with previous meta-reinforcement learning approaches.
翻译:深强化学习展示了与梯度下降相适应的神经网络在有限环境中解决复杂任务的潜力,然而,这些神经系统是产生专门剂的学习迟缓的学习者,除了其培训课程外没有继续学习的机制。相反,生物合成可塑性具有持久性和多重性,并假设在诸如工作记忆和认知灵活性等行政职能中发挥关键作用,从而有可能支持更高效和通用的学习能力。受此启发,我们提议建立具有动态重量的网络,能够持续进行自我调整,作为其当前合成状态和行动反向反馈的函数,而不是固定的网络配置。由此产生的模型MetDDS(Met-Opimized Dynal Synaps)是一个广泛适用的元加强学习系统,能够在代理政策空间学习高效和有力的控制规则。一个具有动态神经的单一层可以进行一线学习,将导航原则推广到看不见的环境,并展示一种强大的学习适应性机动车政策的能力,与以前的元再力学习方法相比较是有利的。