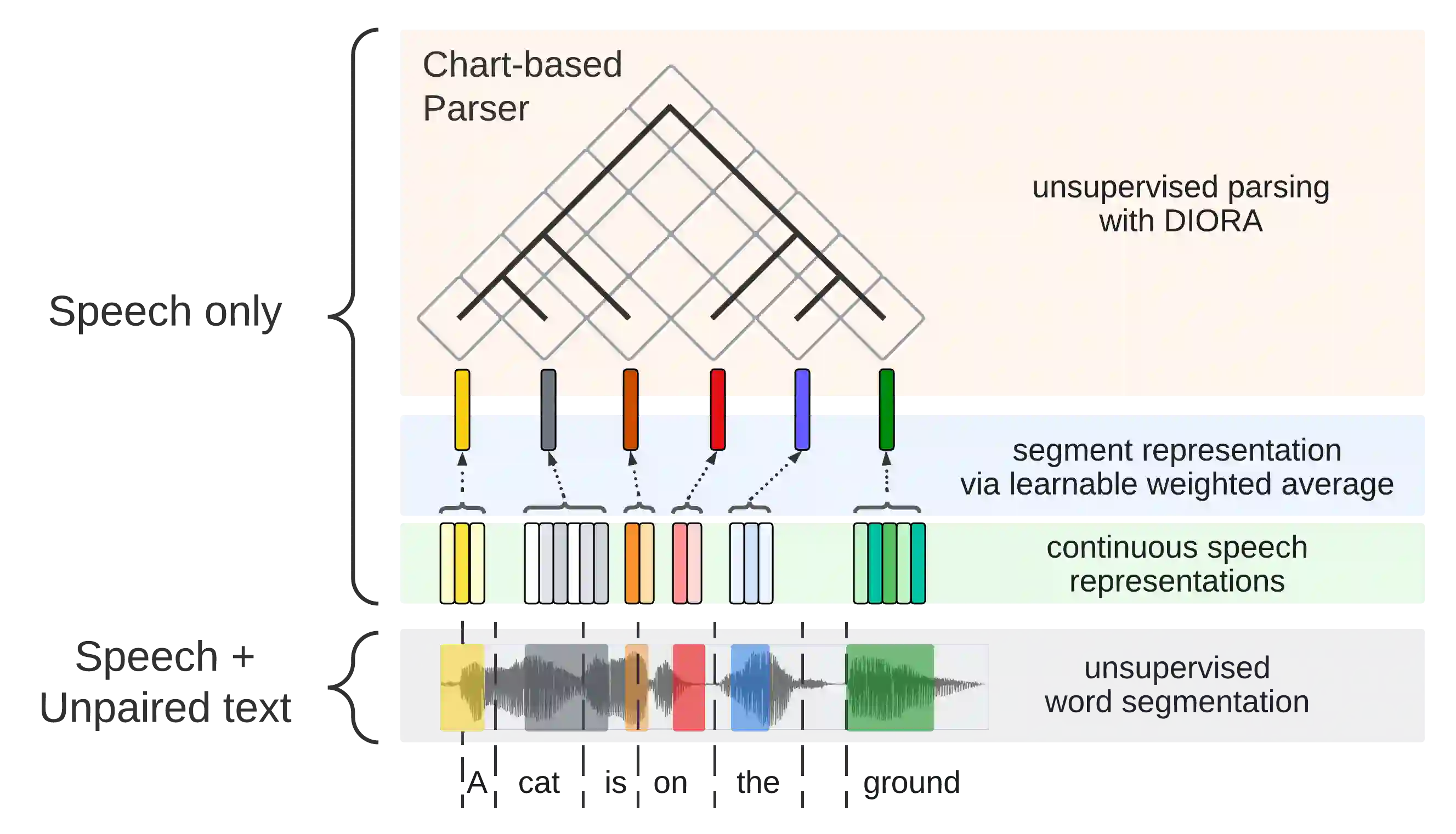
Past work on unsupervised parsing is constrained to written form. In this paper, we present the first study on unsupervised spoken constituency parsing given unlabeled spoken sentences and unpaired textual data. The goal is to determine the spoken sentences' hierarchical syntactic structure in the form of constituency parse trees, such that each node is a span of audio that corresponds to a constituent. We compare two approaches: (1) cascading an unsupervised automatic speech recognition (ASR) model and an unsupervised parser to obtain parse trees on ASR transcripts, and (2) direct training an unsupervised parser on continuous word-level speech representations. This is done by first splitting utterances into sequences of word-level segments, and aggregating self-supervised speech representations within segments to obtain segment embeddings. We find that separately training a parser on the unpaired text and directly applying it on ASR transcripts for inference produces better results for unsupervised parsing. Additionally, our results suggest that accurate segmentation alone may be sufficient to parse spoken sentences accurately. Finally, we show the direct approach may learn head-directionality correctly for both head-initial and head-final languages without any explicit inductive bias.
翻译:在本文中,我们首次介绍关于未受监督的口头发言群落分类的未贴标签的口头发言句子和未贴贴标签的文本数据的研究。目标是以选区剖析树的形式确定口头判决的等级合成结构,使每个节点的音频范围与一个构件相对应。我们比较了两种方法:(1) 将未经监督的自动语音识别模式和未经监督的牧师分隔开来,以获得ASR记录誊本上的剖析树,(2) 直接培训一个不受监督的演讲组别,持续字级语音表述。这是通过首先将口述分割成字级段的顺序,并在各段内集成自我监督的语音表述,以获得部分的嵌入。我们发现,单独培训一个关于未受监督文本的读者,直接应用ASR记录誊本,可以产生更好的结果。此外,我们的结果表明,仅准确的分解方式头部可能足以正确地显示直判的文字。最后,我们最后可以正确地将头部方向的语系头部方向都显示。</s>