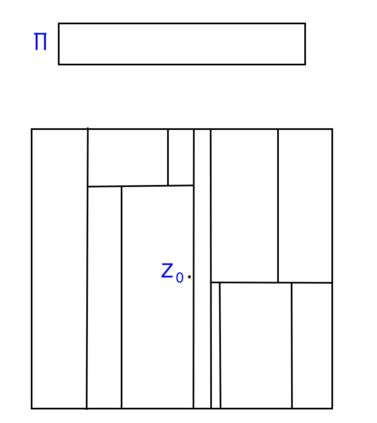
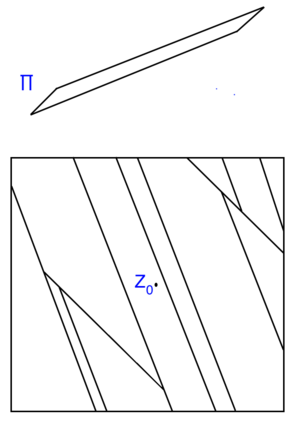
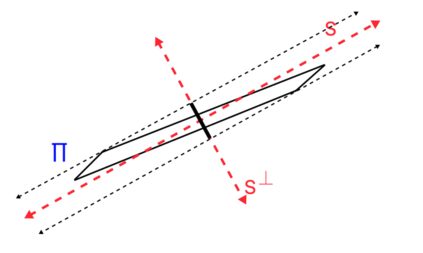
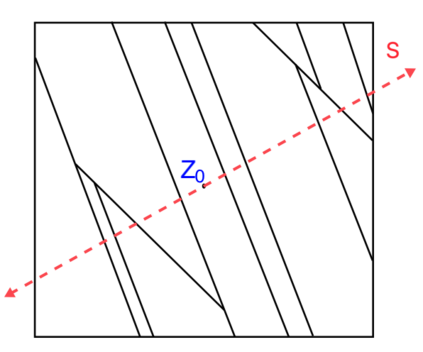
This work studies the statistical advantages of using features comprised of general linear combinations of covariates to partition the data in randomized decision tree and forest regression algorithms. Using random tessellation theory in stochastic geometry, we provide a theoretical analysis of a class of efficiently generated random tree and forest estimators that allow for oblique splits along such features. We call these estimators oblique Mondrian trees and forests, as the trees are generated by first selecting a set of features from linear combinations of the covariates and then running a Mondrian process that hierarchically partitions the data along these features. Generalization error bounds and convergence rates are obtained for the flexible dimension reduction model class of ridge functions (also known as multi-index models), where the output is assumed to depend on a low dimensional relevant feature subspace of the input domain. The results highlight how the risk of these estimators depends on the choice of features and quantify how robust the risk is with respect to error in the estimation of relevant features. The asymptotic analysis also provides conditions on the selected features along which the data is split for these estimators to obtain minimax optimal rates of convergence with respect to the dimension of the relevant feature subspace. Additionally, a lower bound on the risk of axis-aligned Mondrian trees (where features are restricted to the set of covariates) is obtained proving that these estimators are suboptimal for these linear dimension reduction models in general, no matter how the distribution over the covariates used to divide the data at each tree node is weighted.
翻译:暂无翻译