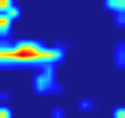
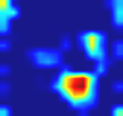
Multi-label image and video classification are fundamental yet challenging tasks in computer vision. The main challenges lie in capturing spatial or temporal dependencies between labels and discovering the locations of discriminative features for each class. In order to overcome these challenges, we propose to use cross-modality attention with semantic graph embedding for multi label classification. Based on the constructed label graph, we propose an adjacency-based similarity graph embedding method to learn semantic label embeddings, which explicitly exploit label relationships. Then our novel cross-modality attention maps are generated with the guidance of learned label embeddings. Experiments on two multi-label image classification datasets (MS-COCO and NUS-WIDE) show our method outperforms other existing state-of-the-arts. In addition, we validate our method on a large multi-label video classification dataset (YouTube-8M Segments) and the evaluation results demonstrate the generalization capability of our method.
翻译:多标签图像和视频分类是计算机愿景中根本性但具有挑战性的任务。主要挑战在于捕捉标签之间的空间或时间依赖性和发现每一类歧视特征的位置。为了克服这些挑战,我们提议使用跨模式关注,用语义图嵌入多标签分类。基于构建的标签图,我们建议采用基于相邻基相似图嵌入方法学习语义标签嵌入,这明确利用了标签关系。然后,我们的新颖的跨模式关注地图通过学习的标签嵌入指南生成。关于两个多标签图像分类数据集(MS-COCO和NUS-WIDE)的实验显示了我们的方法优于其他现有状态。此外,我们还验证了我们关于大型多标签视频分类数据集(YouTube-8M sections)的方法,评估结果显示了我们方法的通用能力。