【论文推荐】最新六篇视频分类相关论文—层次标签推断、知识图谱、CNNs、DAiSEE、表观和关系网络、转移学习
【导读】专知内容组整理了最近六篇视频分类(Video Classification)相关文章,为大家进行介绍,欢迎查看!
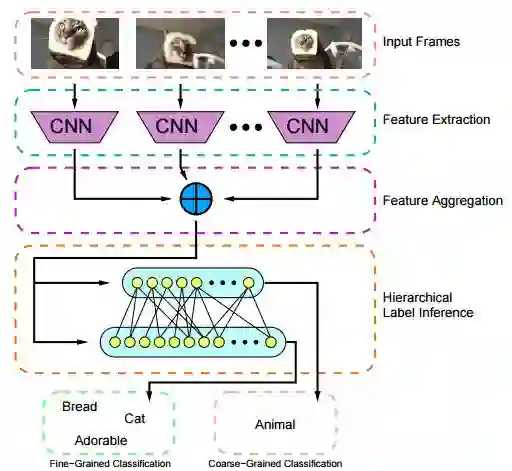
1. Hierarchical Label Inference for Video Classification(基于层次标签推断的视频分类)
作者:Nelson Nauata, Jonathan Smith, Greg Mori
摘要:Videos are a rich source of high-dimensional structured data, with a wide range of interacting components at varying levels of granularity. In order to improve understanding of unconstrained internet videos, it is important to consider the role of labels at separate levels of abstraction. In this paper, we consider the use of the Bidirectional Inference Neural Network (BINN) for performing graph-based inference in label space for the task of video classification. We take advantage of the inherent hierarchy between labels at increasing granularity. The BINN is evaluated on the first and second release of the YouTube-8M large scale multilabel video dataset. Our results demonstrate the effectiveness of BINN, achieving significant improvements against baseline models.
期刊:arXiv, 2018年1月22日
网址:
http://www.zhuanzhi.ai/document/f07570510fbb7f276a8f0ddeab44513d
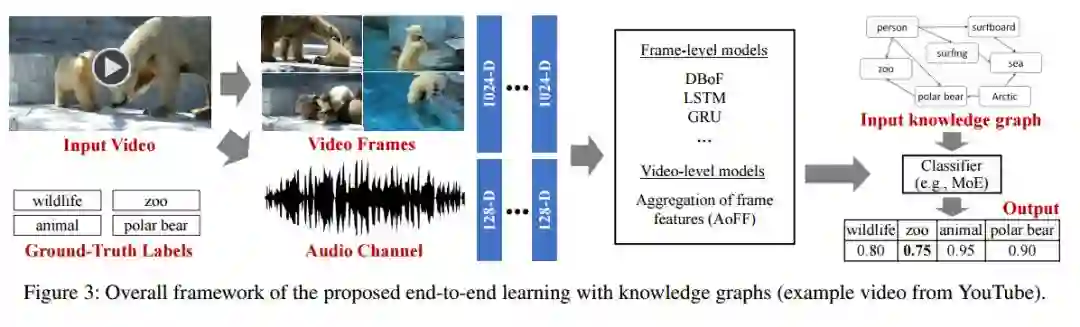
2. End-to-End Video Classification with Knowledge Graphs(基于知识图谱的端到端视频分类)
作者:Fang Yuan,Zhe Wang,Jie Lin,Luis Fernando D'Haro,Kim Jung Jae,Zeng Zeng,Vijay Chandrasekhar
摘要:Video understanding has attracted much research attention especially since the recent availability of large-scale video benchmarks. In this paper, we address the problem of multi-label video classification. We first observe that there exists a significant knowledge gap between how machines and humans learn. That is, while current machine learning approaches including deep neural networks largely focus on the representations of the given data, humans often look beyond the data at hand and leverage external knowledge to make better decisions. Towards narrowing the gap, we propose to incorporate external knowledge graphs into video classification. In particular, we unify traditional "knowledgeless" machine learning models and knowledge graphs in a novel end-to-end framework. The framework is flexible to work with most existing video classification algorithms including state-of-the-art deep models. Finally, we conduct extensive experiments on the largest public video dataset YouTube-8M. The results are promising across the board, improving mean average precision by up to 2.9%.
期刊:arXiv, 2017年11月6日
网址:
http://www.zhuanzhi.ai/document/455ce5f902f940357282ca178d36529a
3. Video Classification With CNNs: Using The Codec As A Spatio-Temporal Activity Sensor(CNNs视频分类:利用Codec作为时空活动感知器)
作者:Aaron Chadha,Alhabib Abbas,Yiannis Andreopoulos
摘要:We investigate video classification via a two-stream convolutional neural network (CNN) design that directly ingests information extracted from compressed video bitstreams. Our approach begins with the observation that all modern video codecs divide the input frames into macroblocks (MBs). We demonstrate that selective access to MB motion vector (MV) information within compressed video bitstreams can also provide for selective, motion-adaptive, MB pixel decoding (a.k.a., MB texture decoding). This in turn allows for the derivation of spatio-temporal video activity regions at extremely high speed in comparison to conventional full-frame decoding followed by optical flow estimation. In order to evaluate the accuracy of a video classification framework based on such activity data, we independently train two CNN architectures on MB texture and MV correspondences and then fuse their scores to derive the final classification of each test video. Evaluation on two standard datasets shows that the proposed approach is competitive to the best two-stream video classification approaches found in the literature. At the same time: (i) a CPU-based realization of our MV extraction is over 977 times faster than GPU-based optical flow methods; (ii) selective decoding is up to 12 times faster than full-frame decoding; (iii) our proposed spatial and temporal CNNs perform inference at 5 to 49 times lower cloud computing cost than the fastest methods from the literature.

期刊:arXiv, 2017年12月20日
网址:
http://www.zhuanzhi.ai/document/745bb3b44fe60618671b8a39129b07f9
4. DAiSEE: Towards User Engagement Recognition in the Wild
作者:Arjun D'Cunha,Abhay Gupta,Kamal Awasthi,Vineeth Balasubramanian
摘要:We introduce DAiSEE, the largest multi-label video classification dataset comprising of over two-and-a-half million video frames (2,723,882), 9068 video snippets (about 25 hours of recording) captured from 112 users for recognizing user affective states, including engagement, in the wild. In addition to engagement, it also includes associated affective states of boredom, confusion, and frustration, which are relevant to such applications. The dataset has four levels of labels from very low to very high for each of the affective states, collected using crowd annotators and correlated with a gold standard annotation obtained from a team of expert psychologists. We have also included benchmark results on this dataset using state-of-the-art video classification methods that are available today, and the baselines on each of the labels is included with this dataset. To the best of our knowledge, DAiSEE is the first and largest such dataset in this domain. We believe that DAiSEE will provide the research community with challenges in feature extraction, context-based inference, and development of suitable machine learning methods for related tasks, thus providing a springboard for further research.

期刊:arXiv, 2017年12月15日
网址:
http://www.zhuanzhi.ai/document/6a9f2d36f4933831d014b390a9add57d
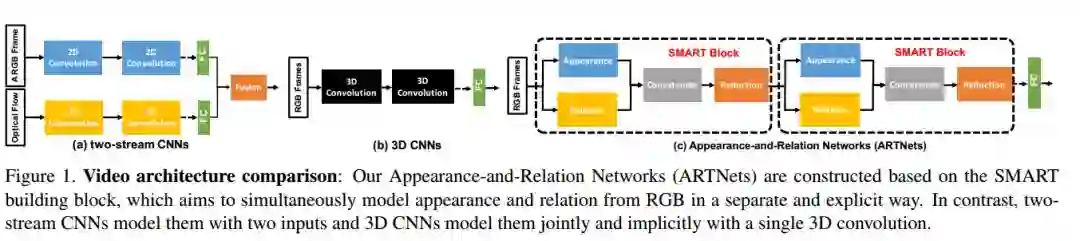
5. Appearance-and-Relation Networks for Video Classification(基于表观和关系网络的视频分类)
作者:Limin Wang,Wei Li,Wen Li,Luc Van Gool
摘要:Spatiotemporal feature learning in videos is a fundamental and difficult problem in computer vision. This paper presents a new architecture, termed as Appearance-and-Relation Network (ARTNet), to learn video representation in an end-to-end manner. ARTNets are constructed by stacking multiple generic building blocks, called as SMART, whose goal is to simultaneously model appearance and relation from RGB input in a separate and explicit manner. Specifically, SMART blocks decouple the spatiotemporal learning module into an appearance branch for spatial modeling and a relation branch for temporal modeling. The appearance branch is implemented based on the linear combination of pixels or filter responses in each frame, while the relation branch is designed based on the multiplicative interactions between pixels or filter responses across multiple frames. We perform experiments on three action recognition benchmarks: Kinetics, UCF101, and HMDB51, demonstrating that SMART blocks obtain an evident improvement over 3D convolutions for spatiotemporal feature learning. Under the same training setting, ARTNets achieve superior performance on these three datasets to the existing state-of-the-art methods.
期刊:arXiv, 2017年11月25日
网址:
http://www.zhuanzhi.ai/document/2689a0ada05c6b1c299873f322943e5b
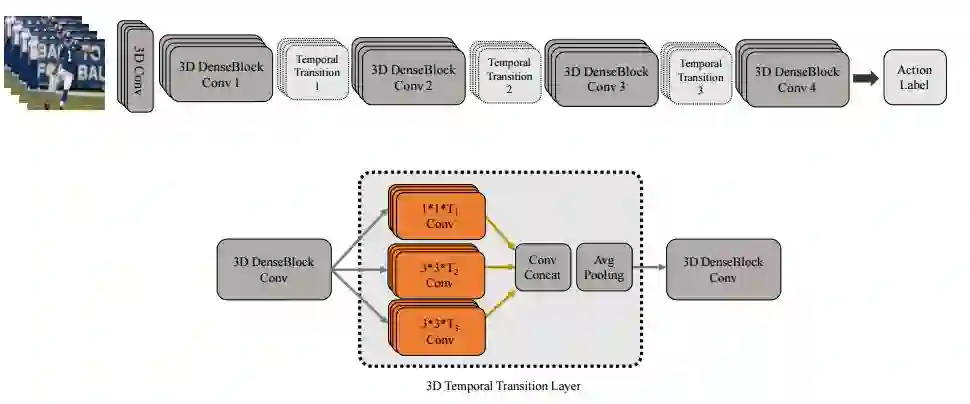
6. Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification(时序3D ConvNets:视频分类的新架构和转移学习)
作者:Ali Diba,Mohsen Fayyaz,Vivek Sharma,Amir Hossein Karami,Mohammad Mahdi Arzani,Rahman Yousefzadeh,Luc Van Gool
摘要:The work in this paper is driven by the question how to exploit the temporal cues available in videos for their accurate classification, and for human action recognition in particular? Thus far, the vision community has focused on spatio-temporal approaches with fixed temporal convolution kernel depths. We introduce a new temporal layer that models variable temporal convolution kernel depths. We embed this new temporal layer in our proposed 3D CNN. We extend the DenseNet architecture - which normally is 2D - with 3D filters and pooling kernels. We name our proposed video convolutional network `Temporal 3D ConvNet'~(T3D) and its new temporal layer `Temporal Transition Layer'~(TTL). Our experiments show that T3D outperforms the current state-of-the-art methods on the HMDB51, UCF101 and Kinetics datasets. The other issue in training 3D ConvNets is about training them from scratch with a huge labeled dataset to get a reasonable performance. So the knowledge learned in 2D ConvNets is completely ignored. Another contribution in this work is a simple and effective technique to transfer knowledge from a pre-trained 2D CNN to a randomly initialized 3D CNN for a stable weight initialization. This allows us to significantly reduce the number of training samples for 3D CNNs. Thus, by finetuning this network, we beat the performance of generic and recent methods in 3D CNNs, which were trained on large video datasets, e.g. Sports-1M, and finetuned on the target datasets, e.g. HMDB51/UCF101. The T3D codes will be released
期刊:arXiv, 2017年11月22日
网址:
http://www.zhuanzhi.ai/document/f1499cb1876a1b27643fd45f692458e6
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!




