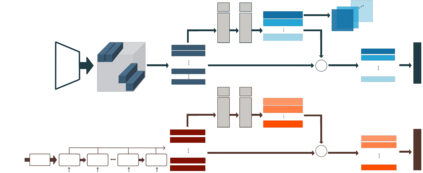
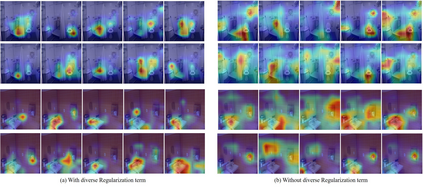
Visual-semantic embedding enables various tasks such as image-text retrieval, image captioning, and visual question answering. The key to successful visual-semantic embedding is to express visual and textual data properly by accounting for their intricate relationship. While previous studies have achieved much advance by encoding the visual and textual data into a joint space where similar concepts are closely located, they often represent data by a single vector ignoring the presence of multiple important components in an image or text. Thus, in addition to the joint embedding space, we propose a novel multi-head self-attention network to capture various components of visual and textual data by attending to important parts in data. Our approach achieves the new state-of-the-art results in image-text retrieval tasks on MS-COCO and Flicker30K datasets. Through the visualization of the attention maps that capture distinct semantic components at multiple positions in the image and the text, we demonstrate that our method achieves an effective and interpretable visual-semantic joint space.
翻译:视觉- 语义嵌入使图像- 文字检索、 图像说明和视觉问题解答等各种任务得以解答 。 成功视觉- 语义嵌入的关键是正确表达视觉和文字数据, 并解释其复杂的关系 。 虽然以前的研究已经取得了很大进步, 将视觉和文字数据编码到一个类似概念所在的联合空间, 但是它们往往代表着单个矢量的数据, 忽略图像或文字中多个重要组成部分的存在 。 因此, 除了联合嵌入空间外, 我们提议建立一个新的多头自省网络, 通过关注数据中的重要部分来捕捉视觉和文字数据的各个组成部分 。 我们的方法在 MS- CO 和 Flicker30K 数据集的图像- 文本检索任务中实现了新的最新结果 。 通过对关注地图的可视化, 在图像和文本的多个位置上捕捉到不同的语义组成部分, 我们证明我们的方法实现了一个有效和可解释的视觉- 语义联合空间 。