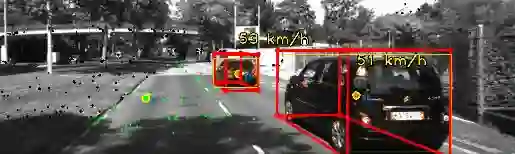
Most classical SLAM systems rely on the static scene assumption, which limits their applicability in real world scenarios. Recent SLAM frameworks have been proposed to simultaneously track the camera and moving objects. However they are often unable to estimate the canonical pose of the objects and exhibit a low object tracking accuracy. To solve this problem we propose TwistSLAM++, a semantic, dynamic, SLAM system that fuses stereo images and LiDAR information. Using semantic information, we track potentially moving objects and associate them to 3D object detections in LiDAR scans to obtain their pose and size. Then, we perform registration on consecutive object scans to refine object pose estimation. Finally, object scans are used to estimate the shape of the object and constrain map points to lie on the estimated surface within the BA. We show on classical benchmarks that this fusion approach based on multimodal information improves the accuracy of object tracking.
翻译:大多数传统的SLAM系统都依赖静态场景假设,这限制了其在现实世界情景中的适用性。最近提出的SLAM框架是为了同时跟踪相机和移动物体。但是,它们往往无法估计物体的金刚石形状和显示低的物体跟踪准确性。为了解决这个问题,我们建议TwiistSLAM+++,一个将立体图像和LIDAR信息结合起来的语义、动态和SLAMM系统。我们利用语义信息,追踪可能移动的物体,并将其与LiDAR扫描中的三维物体探测联系起来,以获得其形状和大小。然后,我们登记连续的物体扫描,以完善物体的测深。最后,物体扫描用于估计物体的形状和限制地图点位于BA的估计表面。我们用传统基准显示,这种基于多式信息的聚合方法提高了物体跟踪的准确性。