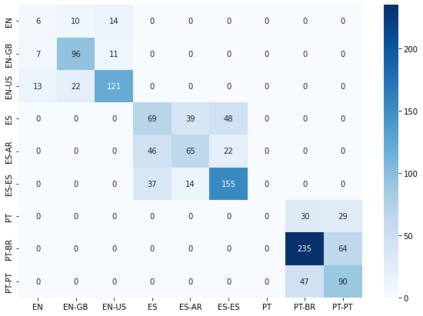
Language identification is an important first step in many IR and NLP applications. Most publicly available language identification datasets, however, are compiled under the assumption that the gold label of each instance is determined by where texts are retrieved from. Research has shown that this is a problematic assumption, particularly in the case of very similar languages (e.g., Croatian and Serbian) and national language varieties (e.g., Brazilian and European Portuguese), where texts may contain no distinctive marker of the particular language or variety. To overcome this important limitation, this paper presents DSL True Labels (DSL-TL), the first human-annotated multilingual dataset for language variety identification. DSL-TL contains a total of 12,900 instances in Portuguese, split between European Portuguese and Brazilian Portuguese; Spanish, split between Argentine Spanish and Castilian Spanish; and English, split between American English and British English. We trained multiple models to discriminate between these language varieties, and we present the results in detail. The data and models presented in this paper provide a reliable benchmark toward the development of robust and fairer language variety identification systems. We make DSL-TL freely available to the research community.
翻译:语言识别是许多IR和NLP应用中重要的第一步。然而,大多数公开可用的语言识别数据集是在假设每个案例的金标签由从何处检索文本的基础上汇编的。研究显示,这是一个有问题的假设,特别是非常相似的语言(例如克罗地亚语和塞尔维亚语)和民族语言品种(例如巴西语和欧裔葡萄牙语),其中文本可能没有特定语言或种类的独特标志。为了克服这一重要限制,本文件提供了DSL True Label(DSL-TL),这是第一个具有人类注释的多种语言识别数据集。DSL-TL(DSL-TL)包含总共12 900个葡萄牙语案例,由欧洲葡萄牙语和巴西葡萄牙语分割;西班牙语,在阿根廷西班牙语和卡斯蒂利亚西班牙语之间分割;英语,在英语和英语之间分割。我们训练了多种模型,以区分这些语言种类或种类,我们详细介绍结果。本文提供的数据和模型为发展稳健、更公平的语言多样性识别系统提供了可靠的基准。我们免费向研究界提供DSLL-TL。</s>