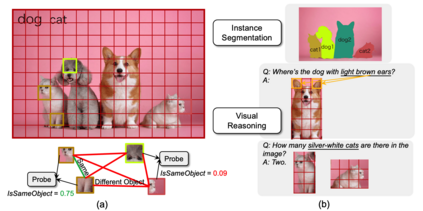
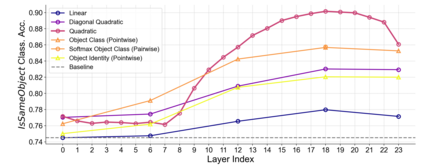
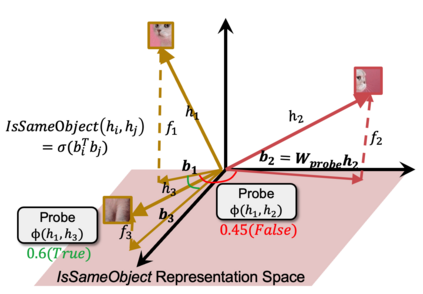
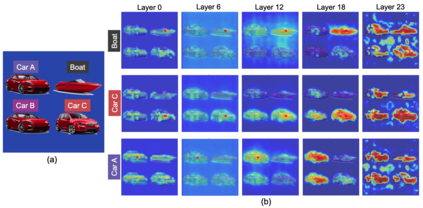
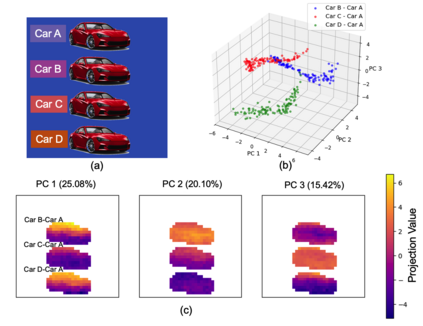
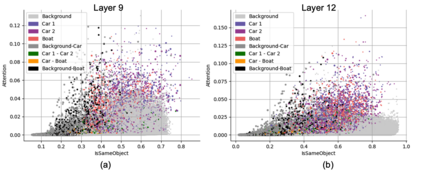
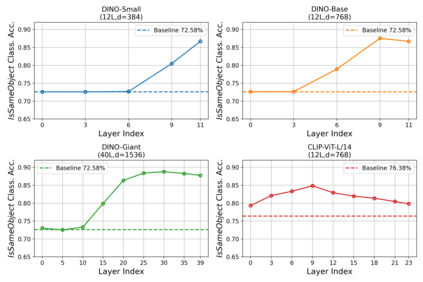
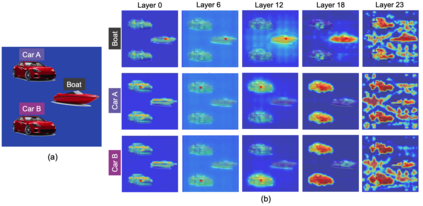
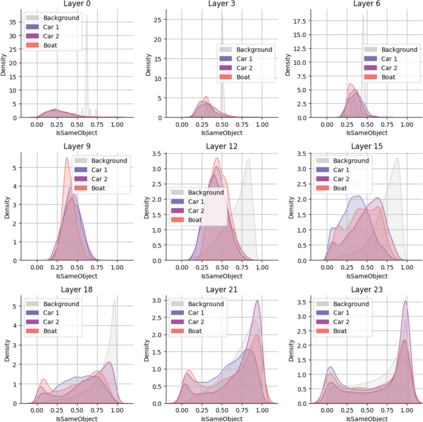
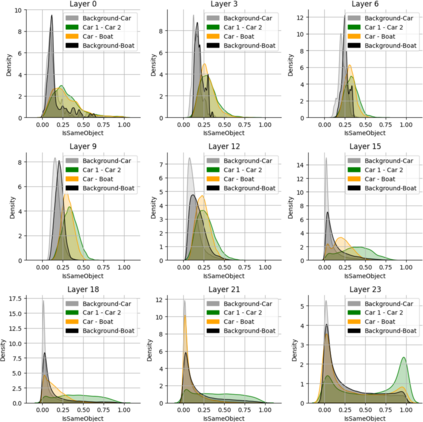
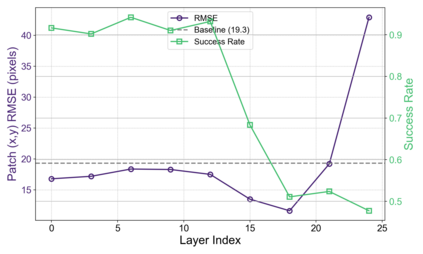
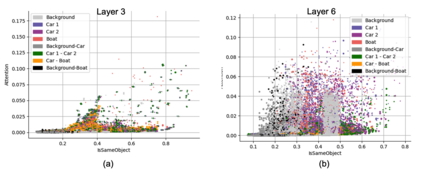
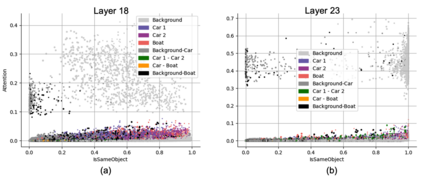
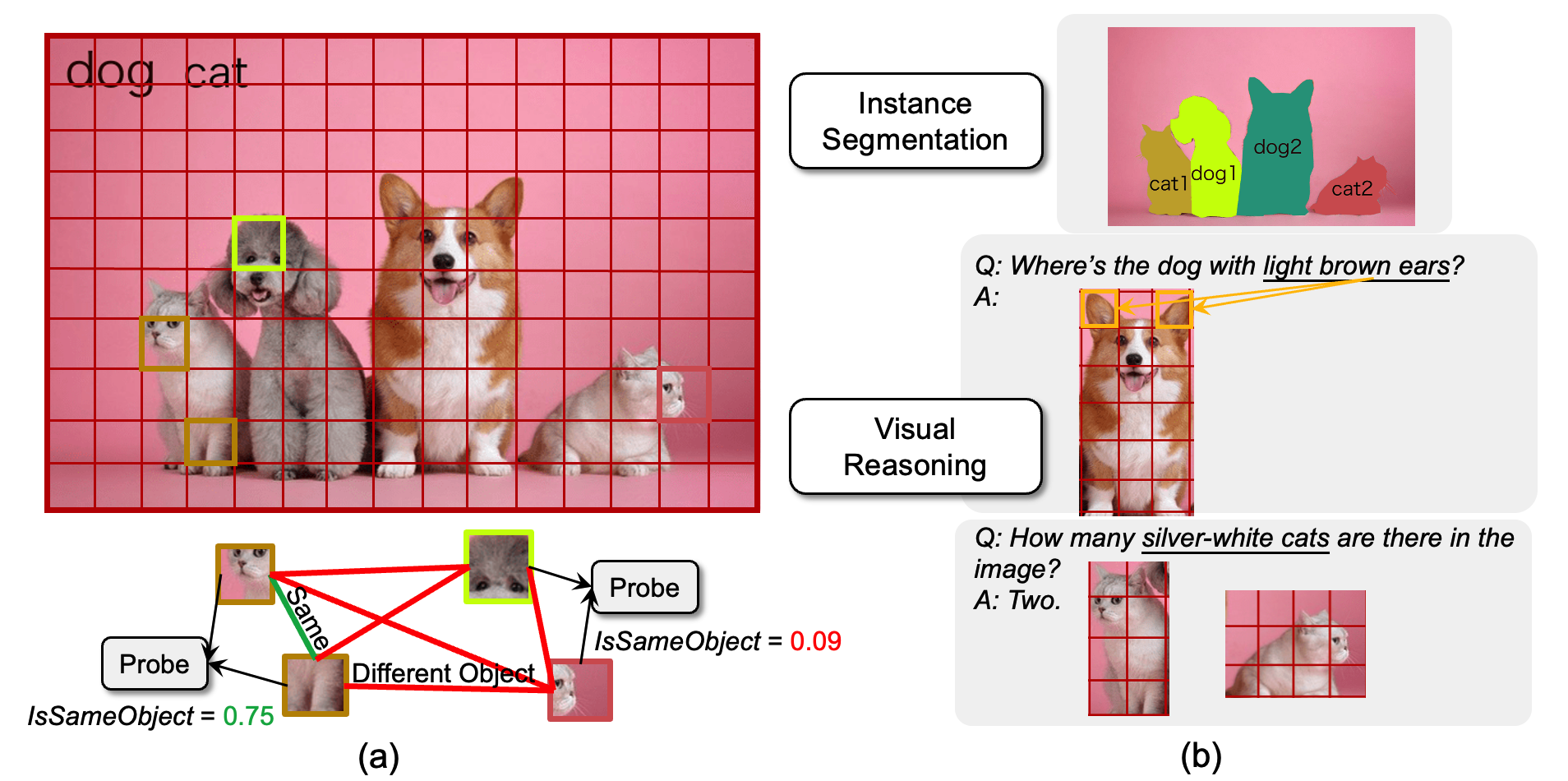
Object binding, the brain's ability to bind the many features that collectively represent an object into a coherent whole, is central to human cognition. It groups low-level perceptual features into high-level object representations, stores those objects efficiently and compositionally in memory, and supports human reasoning about individual object instances. While prior work often imposes object-centric attention (e.g., Slot Attention) explicitly to probe these benefits, it remains unclear whether this ability naturally emerges in pre-trained Vision Transformers (ViTs). Intuitively, they could: recognizing which patches belong to the same object should be useful for downstream prediction and thus guide attention. Motivated by the quadratic nature of self-attention, we hypothesize that ViTs represent whether two patches belong to the same object, a property we term IsSameObject. We decode IsSameObject from patch embeddings across ViT layers using a similarity probe, which reaches over 90% accuracy. Crucially, this object-binding capability emerges reliably in self-supervised ViTs (DINO, MAE, CLIP), but markedly weaker in ImageNet-supervised models, suggesting that binding is not a trivial architectural artifact, but an ability acquired through specific pretraining objectives. We further discover that IsSameObject is encoded in a low-dimensional subspace on top of object features, and that this signal actively guides attention. Ablating IsSameObject from model activations degrades downstream performance and works against the learning objective, implying that emergent object binding naturally serves the pretraining objective. Our findings challenge the view that ViTs lack object binding and highlight how symbolic knowledge of "which parts belong together" emerges naturally in a connectionist system.
翻译:暂无翻译