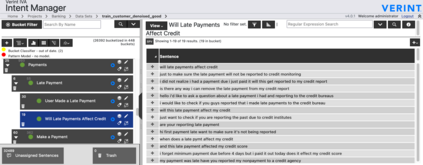
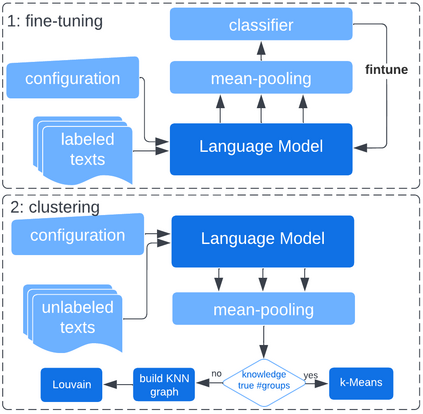
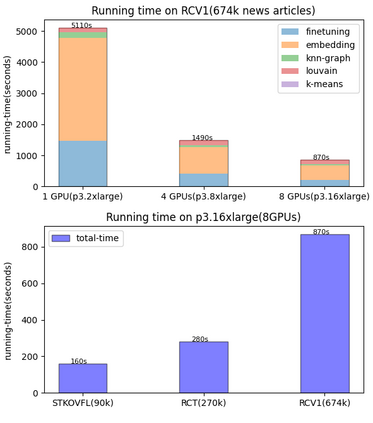
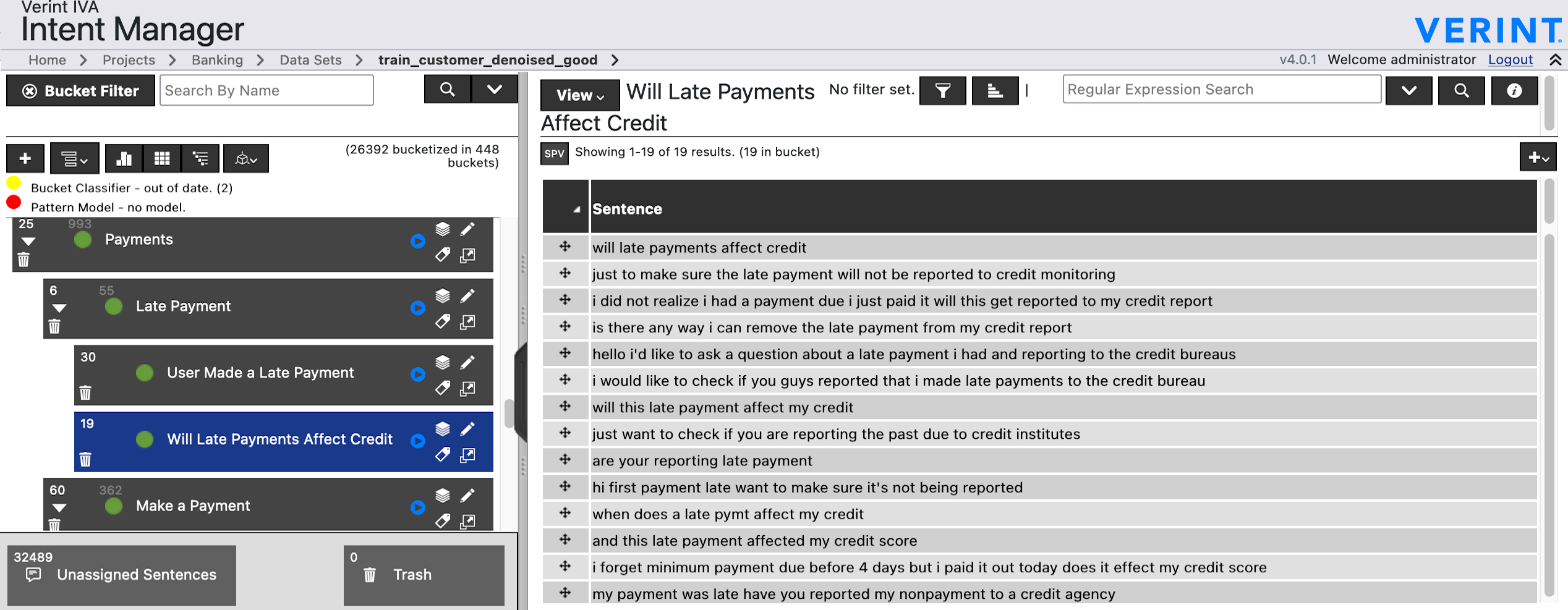
Mining the latent intentions from large volumes of natural language inputs is a key step to help data analysts design and refine Intelligent Virtual Assistants (IVAs) for customer service and sales support. We created a flexible and scalable clustering pipeline within the Verint Intent Manager (VIM) that integrates the fine-tuning of language models, a high performing k-NN library and community detection techniques to help analysts quickly surface and organize relevant user intentions from conversational texts. The fine-tuning step is necessary because pre-trained language models cannot encode texts to efficiently surface particular clustering structures when the target texts are from an unseen domain or the clustering task is not topic detection. We describe the pipeline and demonstrate its performance and ability to scale on three real-world text mining tasks. As deployed in the VIM application, this clustering pipeline produces high quality results, improving the performance of data analysts and reducing the time it takes to surface intentions from customer service data, thereby reducing the time it takes to build and deploy IVAs in new domains.
翻译:挖掘大量自然语言投入的潜在意图是帮助数据分析员设计和完善用于客户服务和销售支持的智能虚拟助理(IVAs)的关键步骤,我们在Verint Intent经理(VIM)内部创建了灵活和可扩展的集群管道,将语言模型的微调、高效 kNN图书馆和社区探测技术结合起来,帮助分析员快速地浮出水面并从谈话文本中组织相关的用户意图。微调步骤是必要的,因为预先培训的语言模型无法将文本编码成有效表面特定集群结构,当目标文本来自无形域或集群任务不是专题探测时。我们描述管道并展示其绩效和在三种真实世界文本挖掘任务上的规模能力。正如在VIM应用中部署的那样,这种集群管道产生高质量的结果,提高数据分析员的性能,减少用户服务数据表面意图所需的时间,从而减少在新领域建立和部署IVA所需的时间。