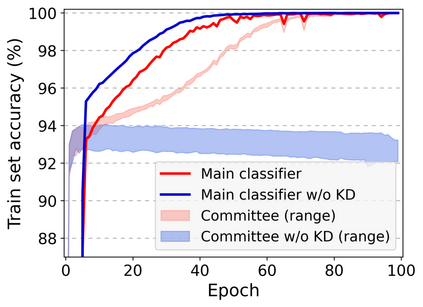
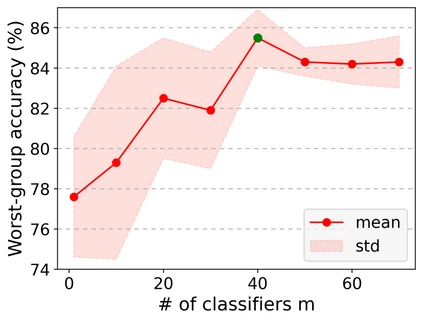
Neural networks are prone to be biased towards spurious correlations between classes and latent attributes exhibited in a major portion of training data, which ruins their generalization capability. This paper proposes a new method for training debiased classifiers with no spurious attribute label. The key idea of the method is to employ a committee of classifiers as an auxiliary module that identifies bias-conflicting data, i.e., data without spurious correlations, and assigns large weights to them when training the main classifier. The committee is learned as a bootstrapped ensemble so that a majority of its classifiers are biased as well as being diverse, and intentionally fail to predict classes of bias-conflicting data accordingly. The consensus within the committee on prediction difficulty thus provides a reliable cue for identifying and weighting bias-conflicting data. Moreover, the committee is also trained with knowledge transferred from the main classifier so that it gradually becomes debiased along with the main classifier and emphasizes more difficult data as training progresses. On five real-world datasets, our method outperforms existing methods using no spurious attribute label like ours and even surpasses those relying on bias labels occasionally.
翻译:神经网络容易偏向于在大部分培训数据中显示的阶级和潜在属性之间的虚假关联,这破坏了其一般化能力。本文件提出一种新的方法,用于培训没有虚假属性标签的有偏见的分类人员。这种方法的关键理念是使用一个分类人员委员会作为辅助模块,确定有偏见的冲突数据,即没有虚假关联的数据,并在培训主要分类人员时给它们分配大量权重。委员会作为一个累累的合谋学习,使其大多数分类人员具有偏向性和多样性,并故意不相应预测有偏见的冲突数据类别。预测困难委员会内的共识因此为识别和加权有偏见的冲突数据提供了可靠的提示。此外,委员会还接受主要分类人员传授的知识的培训,以便逐渐与主要分类人员一起消离偏见,并强调在培训过程中更难掌握数据。在五个现实世界数据集中,我们的方法超越了现有方法,使用了没有虚假属性标签的方法,例如我们的标签,甚至不时不依赖这些标签。