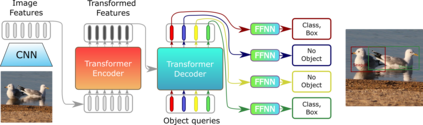
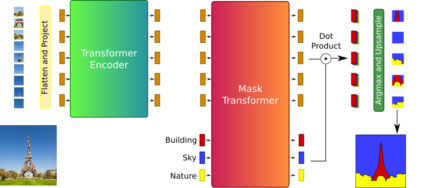
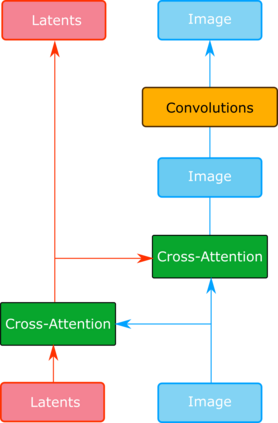
Transformers were initially introduced for natural language processing (NLP) tasks, but fast they were adopted by most deep learning fields, including computer vision. They measure the relationships between pairs of input tokens (words in the case of text strings, parts of images for visual Transformers), termed attention. The cost is exponential with the number of tokens. For image classification, the most common Transformer Architecture uses only the Transformer Encoder in order to transform the various input tokens. However, there are also numerous other applications in which the decoder part of the traditional Transformer Architecture is also used. Here, we first introduce the Attention mechanism (Section 1), and then the Basic Transformer Block including the Vision Transformer (Section 2). Next, we discuss some improvements of visual Transformers to account for small datasets or less computation(Section 3). Finally, we introduce Visual Transformers applied to tasks other than image classification, such as detection, segmentation, generation and training without labels (Section 4) and other domains, such as video or multimodality using text or audio data (Section 5).
翻译:转换器最初是为自然语言处理(NLP)任务引入的,但它们很快被包括计算机视觉在内的多数深度学习领域所采用。它们测量输入令牌(文本字符串中的单词,对于视觉转换器来说是图像部分)之间的关系,称为注意力。成本随令牌数呈指数级增长。对于图像分类,最常见的Transformer Architecture仅使用Transformer编码器来转换各个输入令牌。但是,在许多其他应用中,传统的Transformer Architecture的解码器部分也被使用。在这里,我们首先介绍Attentio机制(第1部分),然后是基本Transformer块,包括Vision Transformer(第2部分)。接下来,我们讨论了一些改进视觉Transformer的方法,以适应较小的数据集或较少的计算(第3部分)。最后,我们介绍了应用于除图像分类之外的其他任务的视觉Transformer,如检测,分割,生成和无标签训练(第4部分),以及使用文本或音频数据的视频或多模态领域(第5部分)。