
论文题目: Unsupervised Pre-training for Natural Language Generation
论文摘要: 最近,由于无监督预训练在促进自然语言理解(NLU)方面取得了令人惊讶的成功以及有效利用大规模未标记语料库的潜力,因此在计算语言学领域正变得越来越受欢迎。但是,无论NLU是否成功,当涉及自然语言生成(NLG)时,无监督预训练的功能只能被部分挖掘。 NLG特质的主要障碍是:文本通常是基于特定的上下文生成的,可能会因目标应用程序而异。结果,像在NLU场景中一样,设计用于预训练的通用体系结构是很难的。此外,在目标任务上学习时保留从预训练中学到的知识也是不容置疑的。这篇综述总结了近期在无监督的预训练下增强NLG系统的工作,特别着重于催化将预训练的模型集成到下游任务中的方法。根据它们处理上述障碍的方式,它们分为基于体系结构的方法和基于策略的方法。还提供了讨论,以提供这两种工作方式之间的进一步相互了解,一些有益的经验现象以及未来工作可能涉及的一些方向。
成为VIP会员查看完整内容
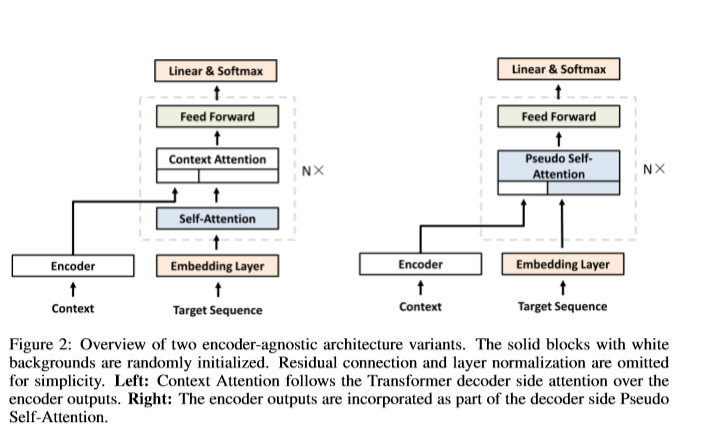

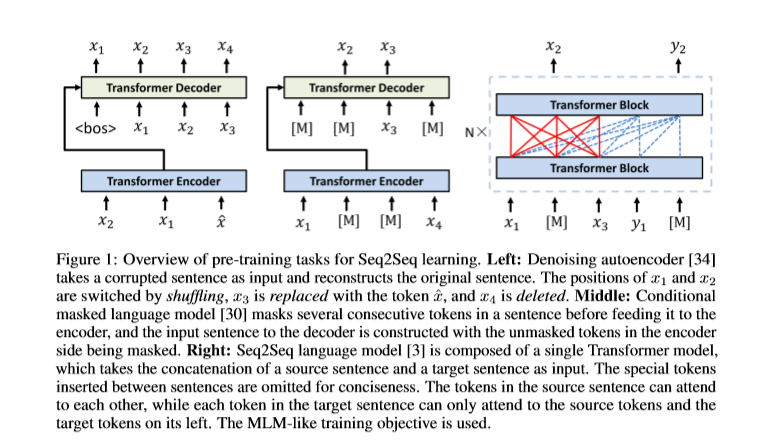
相关内容

专知会员服务
94+阅读 · 2020年4月13日
专知会员服务
33+阅读 · 2020年2月29日
专知会员服务
58+阅读 · 2019年12月2日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
相关主题




相关VIP内容
专知会员服务
94+阅读 · 2020年4月13日
专知会员服务
33+阅读 · 2020年2月29日
专知会员服务
58+阅读 · 2019年12月2日
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日