【论文推荐】最新6篇视觉问答(VQA)相关论文—目标推理、深度循环模型、可解释性、数据可视化、Triplet学习、基准
【导读】专知内容组整理了最近六篇视觉问答(Visual Question Answering)相关文章,为大家进行介绍,欢迎查看!
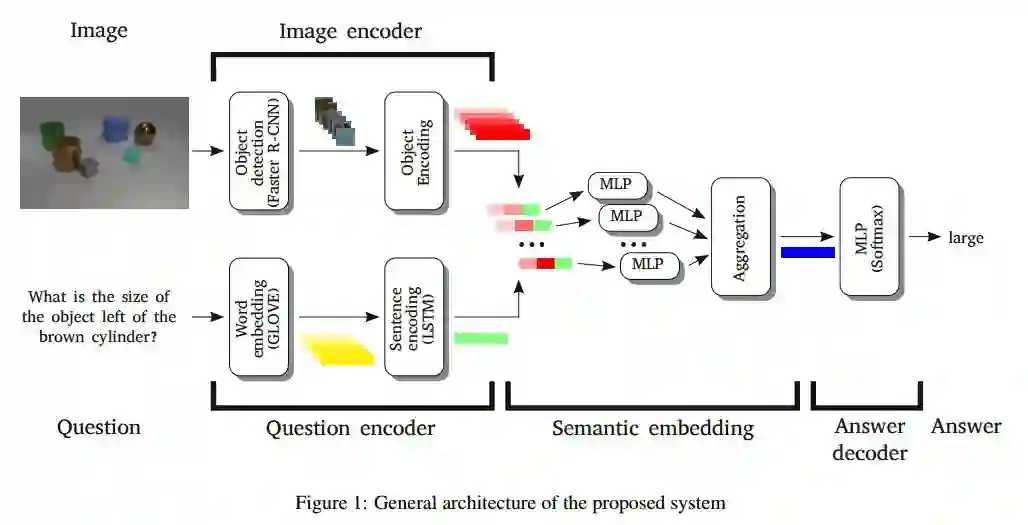
1. Object-based reasoning in VQA(基于目标推理机制的VQA方法)
作者:Mikyas T. Desta,Larry Chen,Tomasz Kornuta
摘要:Visual Question Answering (VQA) is a novel problem domain where multi-modal inputs must be processed in order to solve the task given in the form of a natural language. As the solutions inherently require to combine visual and natural language processing with abstract reasoning, the problem is considered as AI-complete. Recent advances indicate that using high-level, abstract facts extracted from the inputs might facilitate reasoning. Following that direction we decided to develop a solution combining state-of-the-art object detection and reasoning modules. The results, achieved on the well-balanced CLEVR dataset, confirm the promises and show significant, few percent improvements of accuracy on the complex "counting" task.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/e66cdd3b106af1c0bc2537aa339de710
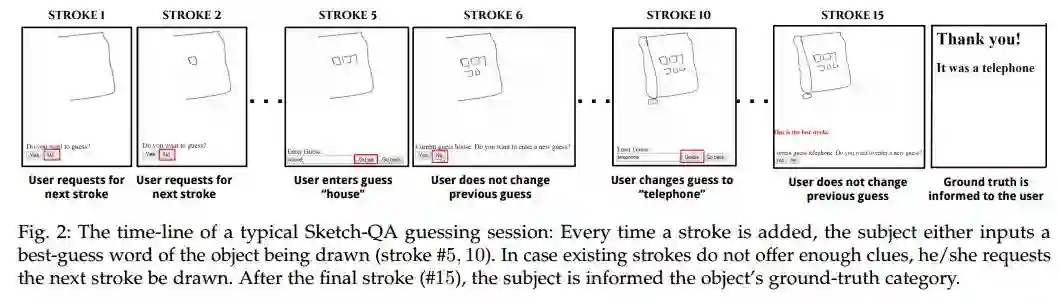
2. Game of Sketches: Deep Recurrent Models of Pictionary-style Word Guessing(草图游戏:绘画风格单词猜测的深度循环模型)
作者:Ravi Kiran Sarvadevabhatla,Shiv Surya,Trisha Mittal,Venkatesh Babu Radhakrishnan
摘要:The ability of intelligent agents to play games in human-like fashion is popularly considered a benchmark of progress in Artificial Intelligence. Similarly, performance on multi-disciplinary tasks such as Visual Question Answering (VQA) is considered a marker for gauging progress in Computer Vision. In our work, we bring games and VQA together. Specifically, we introduce the first computational model aimed at Pictionary, the popular word-guessing social game. We first introduce Sketch-QA, an elementary version of Visual Question Answering task. Styled after Pictionary, Sketch-QA uses incrementally accumulated sketch stroke sequences as visual data. Notably, Sketch-QA involves asking a fixed question ("What object is being drawn?") and gathering open-ended guess-words from human guessers. We analyze the resulting dataset and present many interesting findings therein. To mimic Pictionary-style guessing, we subsequently propose a deep neural model which generates guess-words in response to temporally evolving human-drawn sketches. Our model even makes human-like mistakes while guessing, thus amplifying the human mimicry factor. We evaluate our model on the large-scale guess-word dataset generated via Sketch-QA task and compare with various baselines. We also conduct a Visual Turing Test to obtain human impressions of the guess-words generated by humans and our model. Experimental results demonstrate the promise of our approach for Pictionary and similarly themed games.
期刊:arXiv, 2018年1月29日
网址:
http://www.zhuanzhi.ai/document/ccb7ef06ebe6d7e4607f20dbc41b25c6
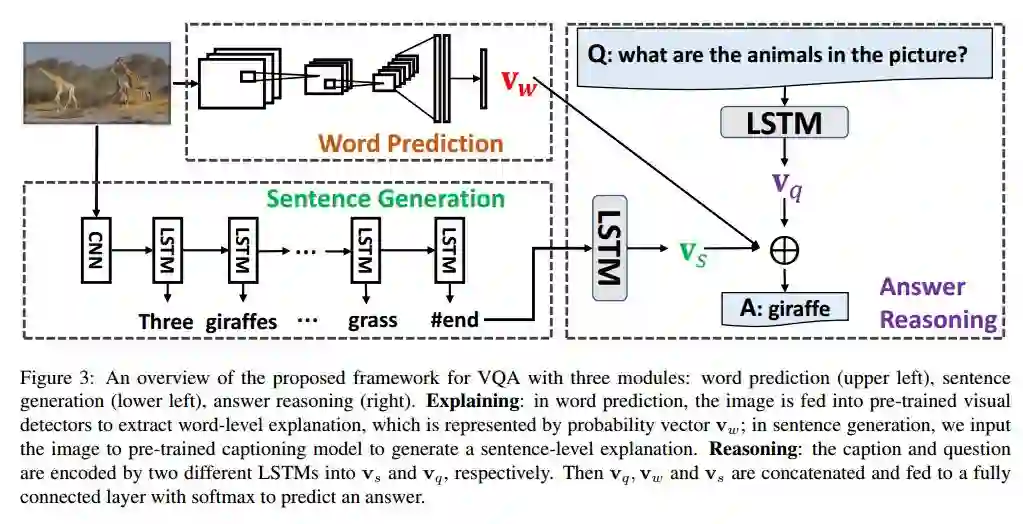
3. Tell-and-Answer: Towards Explainable Visual Question Answering using Attributes and Captions(Tell-and-Answer: 基于属性和字幕的可解释性视觉问答)
作者:Qing Li,Jianlong Fu,Dongfei Yu,Tao Mei,Jiebo Luo
摘要:Visual Question Answering (VQA) has attracted attention from both computer vision and natural language processing communities. Most existing approaches adopt the pipeline of representing an image via pre-trained CNNs, and then using the uninterpretable CNN features in conjunction with the question to predict the answer. Although such end-to-end models might report promising performance, they rarely provide any insight, apart from the answer, into the VQA process. In this work, we propose to break up the end-to-end VQA into two steps: explaining and reasoning, in an attempt towards a more explainable VQA by shedding light on the intermediate results between these two steps. To that end, we first extract attributes and generate descriptions as explanations for an image using pre-trained attribute detectors and image captioning models, respectively. Next, a reasoning module utilizes these explanations in place of the image to infer an answer to the question. The advantages of such a breakdown include: (1) the attributes and captions can reflect what the system extracts from the image, thus can provide some explanations for the predicted answer; (2) these intermediate results can help us identify the inabilities of both the image understanding part and the answer inference part when the predicted answer is wrong. We conduct extensive experiments on a popular VQA dataset and dissect all results according to several measurements of the explanation quality. Our system achieves comparable performance with the state-of-the-art, yet with added benefits of explainability and the inherent ability to further improve with higher quality explanations.
期刊:arXiv, 2018年1月27日
网址:
http://www.zhuanzhi.ai/document/402b024e93b4bf9fc5d4e31e090ffd80
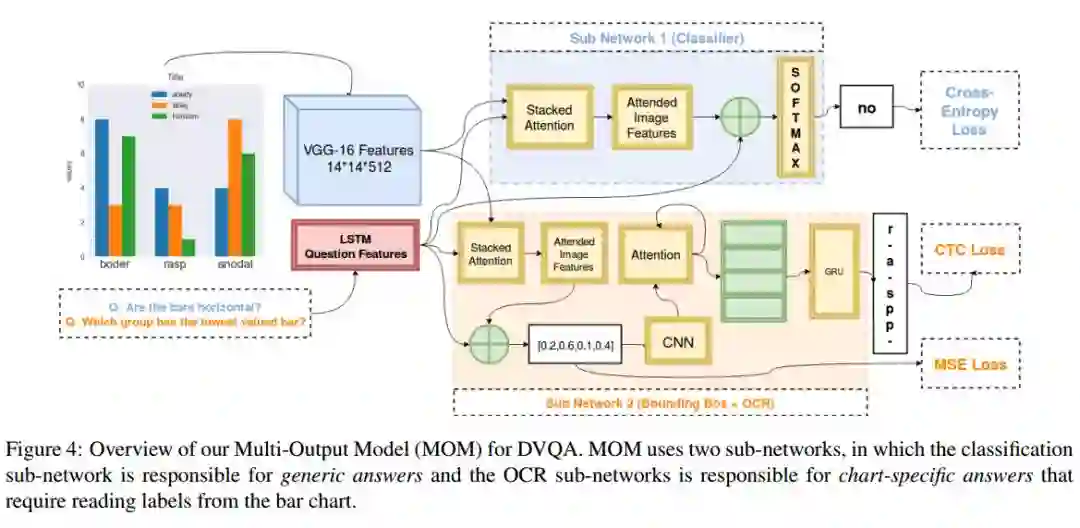
4. DVQA:Understanding Data Visualizations via Question Answering(DVQA:通过问答来理解数据可视化)
作者:Kushal Kafle,Scott Cohen,Brian Price,Christopher Kanan
摘要:Bar charts are an effective way for humans to convey information to each other, but today's algorithms cannot parse them. Existing methods fail when faced with minor variations in appearance. Here, we present DVQA, a dataset that tests many aspects of bar chart understanding in a question answering framework. Unlike visual question answering (VQA), DVQA requires processing words and answers that are unique to a particular bar chart. State-of-the-art VQA algorithms perform poorly on DVQA, and we propose two strong baselines that perform considerably better. Our work will enable algorithms to automatically extract semantic information from vast quantities of literature in science, business, and other areas.
期刊:arXiv, 2018年1月25日
网址:
http://www.zhuanzhi.ai/document/416ee1ab66f798bc7f64f8c308fc3628
5. Structured Triplet Learning with POS-tag Guided Attention for Visual Question Answering(VQA : 结构Triplet学习与词性标注结合的注意力机制模型)
作者:Zhe Wang,Xiaoyi Liu,Liangjian Chen,Limin Wang,Yu Qiao,Xiaohui Xie,Charless Fowlkes
摘要:Visual question answering (VQA) is of significant interest due to its potential to be a strong test of image understanding systems and to probe the connection between language and vision. Despite much recent progress, general VQA is far from a solved problem. In this paper, we focus on the VQA multiple-choice task, and provide some good practices for designing an effective VQA model that can capture language-vision interactions and perform joint reasoning. We explore mechanisms of incorporating part-of-speech (POS) tag guided attention, convolutional n-grams, triplet attention interactions between the image, question and candidate answer, and structured learning for triplets based on image-question pairs. We evaluate our models on two popular datasets: Visual7W and VQA Real Multiple Choice. Our final model achieves the state-of-the-art performance of 68.2% on Visual7W, and a very competitive performance of 69.6% on the test-standard split of VQA Real Multiple Choice.
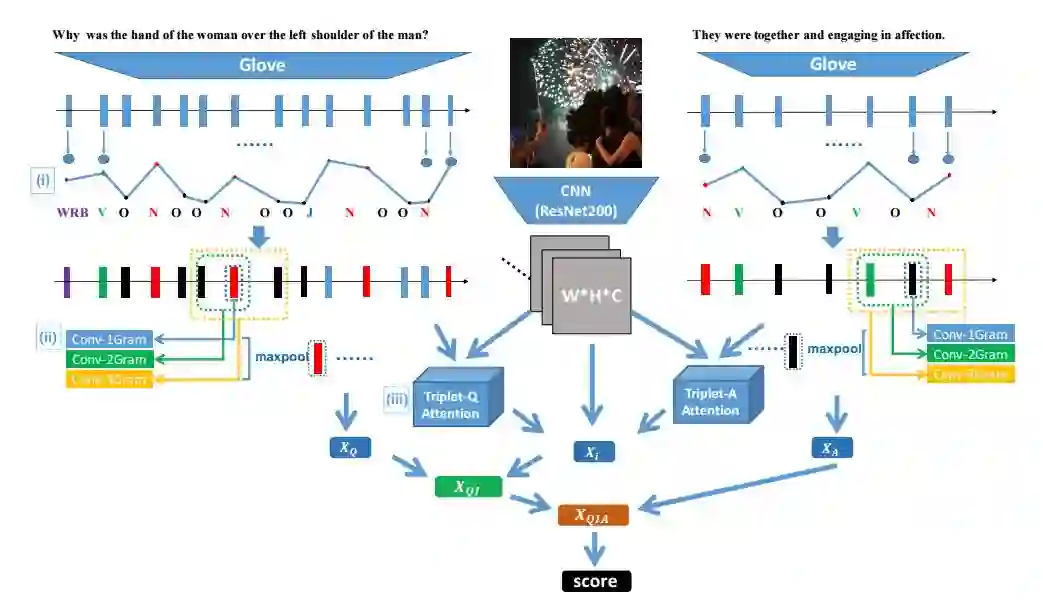
期刊:arXiv, 2018年1月24日
网址:
http://www.zhuanzhi.ai/document/e8c2e558ef97053837bc6dd2d05c829c
6. Benchmark Visual Question Answer Models by using Focus Map(基于聚焦地图的基准的视觉问答模型)
作者:Wenda Qiu,Yueyang Xianzang,Zhekai Zhang
摘要:Inferring and Executing Programs for Visual Reasoning proposes a model for visual reasoning that consists of a program generator and an execution engine to avoid end-to-end models. To show that the model actually learns which objects to focus on to answer the questions, the authors give a visualization of the norm of the gradient of the sum of the predicted answer scores with respect to the final feature map. However, the authors do not evaluate the efficiency of focus map. This paper purposed a method for evaluating it. We generate several kinds of questions to test different keywords. We infer focus maps from the model by asking these questions and evaluate them by comparing with the segmentation graph. Furthermore, this method can be applied to any model if focus maps can be inferred from it. By evaluating focus map of different models on the CLEVR dataset, we will show that CLEVR-iep model has learned where to focus more than end-to-end models.
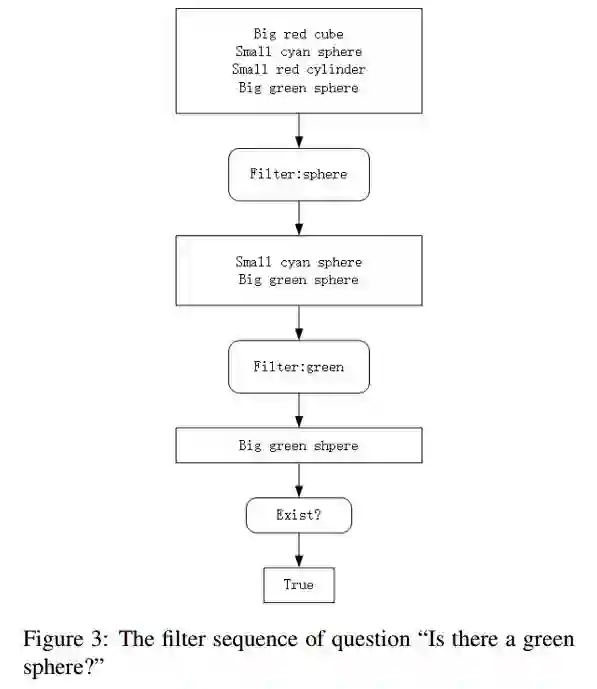
期刊:arXiv, 2018年1月13日
网址:
http://www.zhuanzhi.ai/document/3b9588b2e7574033eff33bae73908cf0
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!





