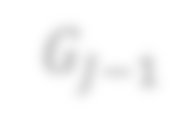The efficiency of Large Language Model~(LLM) inference is often constrained by substantial memory bandwidth and capacity demands. Existing techniques, such as pruning, quantization, and mixture of experts/depth, reduce memory capacity and/or bandwidth consumption at the cost of slight degradation in inference quality. This paper introduces a design solution that further alleviates memory bottlenecks by enhancing the on-chip memory controller in AI accelerators to achieve two main objectives: (1) significantly reducing memory capacity and bandwidth usage through lossless block compression~(e.g., LZ4 and ZSTD) of model weights and key-value (KV) cache without compromising inference quality, and (2) enabling memory bandwidth and energy consumption to scale proportionally with context-dependent dynamic quantization. These goals are accomplished by equipping the on-chip memory controller with mechanisms to improve fine-grained bit-level accessibility and compressibility of weights and KV cache through LLM-aware configuration of in-memory placement and representation. Experimental results on publicly available LLMs demonstrate the effectiveness of this approach, showing memory footprint reductions of 25.2\% for model weights and 46.9\% for KV cache. In addition, our hardware prototype at 4\,GHz and 32 lanes (7\,nm) achieves 8\,TB/s throughput with a modest area overhead (under 3.8\,mm\(^2\)), which underscores the viability of LLM-aware memory control as a key to efficient large-scale inference.
翻译:暂无翻译