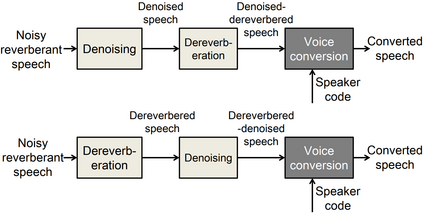
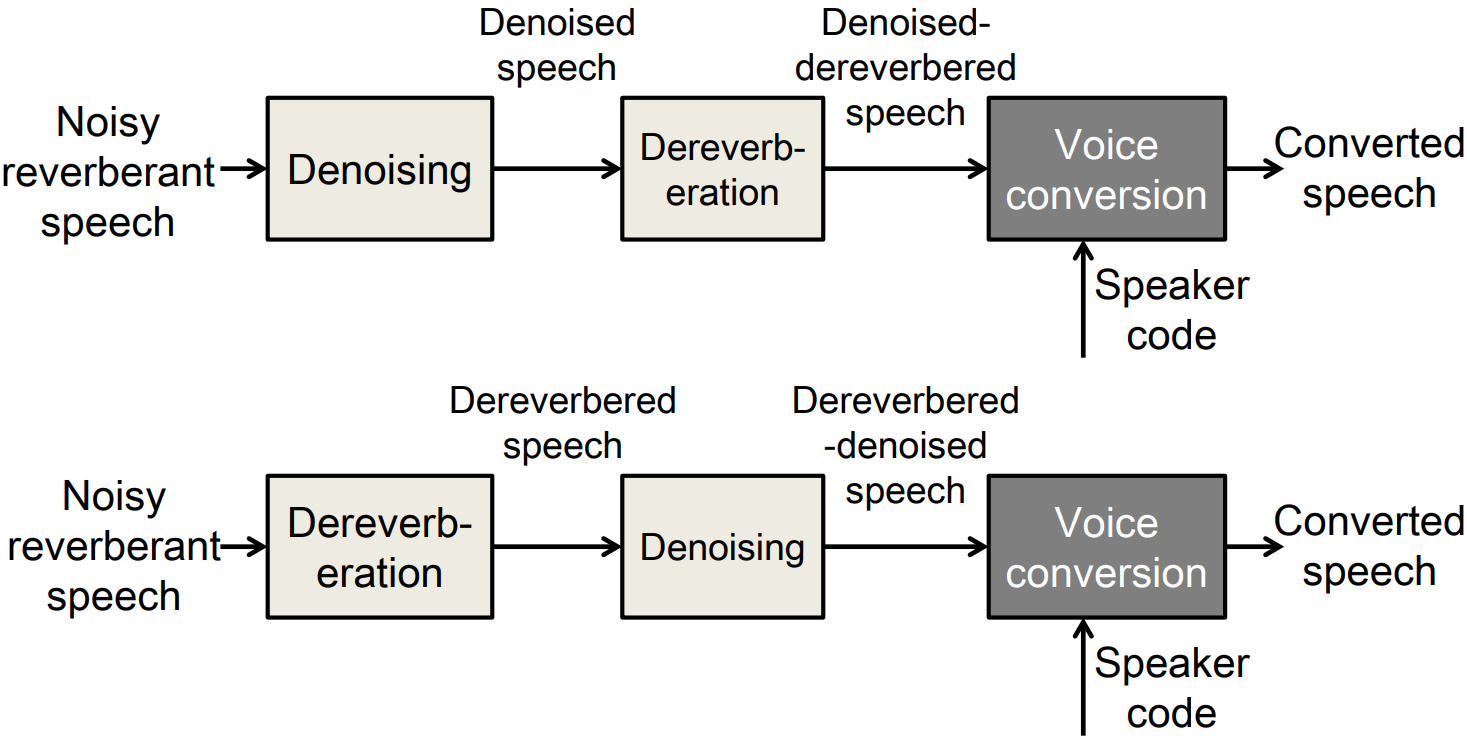
This paper presents a new voice conversion (VC) framework capable of dealing with both additive noise and reverberation, and its performance evaluation. There have been studied some VC researches focusing on real-world circumstances where speech data are interfered with background noise and reverberation. To deal with more practical conditions where no clean target dataset is available, one possible approach is zero-shot VC, but its performance tends to degrade compared with VC using sufficient amount of target speech data. To leverage large amount of noisy-reverberant target speech data, we propose a three-stage VC framework based on denoising process using a pretrained denoising model, dereverberation process using a dereverberation model, and VC process using a nonparallel VC model based on a variational autoencoder. The experimental results show that 1) noise and reverberation additively cause significant VC performance degradation, 2) the proposed method alleviates the adverse effects caused by both noise and reverberation, and significantly outperforms the baseline directly trained on the noisy-reverberant speech data, and 3) the potential degradation introduced by the denoising and dereverberation still causes noticeable adverse effects on VC performance.
翻译:本文介绍了一个新的声音转换框架(VC),能够同时处理添加噪音和反响,并进行业绩评估。已经对VC的一些研究进行了研究,重点是语言数据受到背景噪音和反响干扰的现实世界环境。为了处理没有清洁目标数据集的更实际条件,一种可能的办法是零弹VC,但其性能往往会与VC相比,使用足够数量的目标语音数据降低。为了利用大量噪音和反动目标语音数据,我们提议了一个三阶段VC框架,其基础是使用预先训练的调离模型进行分解过程,使用皮肤变异模型进行剥离过程,以及使用基于变异自动电解变码的无平行VC模型进行VC进程。实验结果显示:(1)噪音和反动添加添加因素导致VC性能严重退化,(2)拟议方法减轻噪音和反动反应造成的有害影响,大大超出直接训练的关于噪音和反动语音语音数据的基准,并大大超越了直接训练的脱动器语音语音语音数据的基准,3)通过持续降解造成潜在退化的原因。