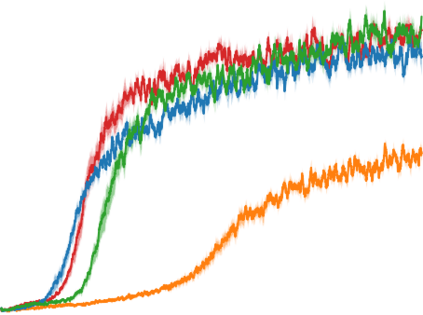
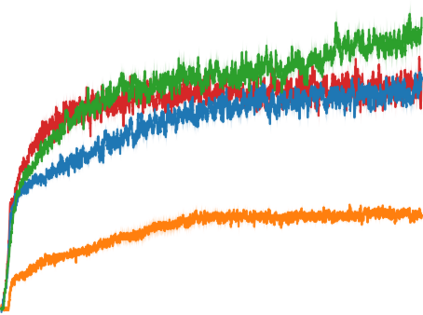
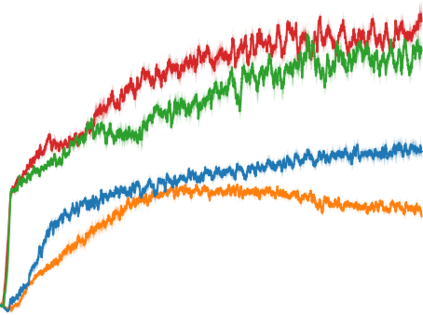
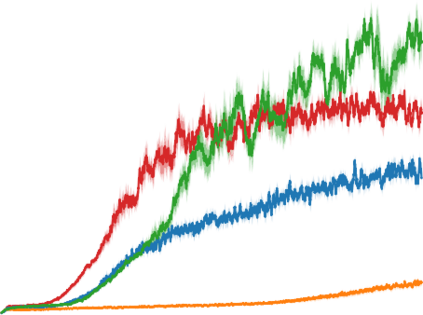
Artificial neural networks are promising for general function approximation but challenging to train on non-independent or non-identically distributed data due to catastrophic forgetting. The experience replay buffer, a standard component in deep reinforcement learning, is often used to reduce forgetting and improve sample efficiency by storing experiences in a large buffer and using them for training later. However, a large replay buffer results in a heavy memory burden, especially for onboard and edge devices with limited memory capacities. We propose memory-efficient reinforcement learning algorithms based on the deep Q-network algorithm to alleviate this problem. Our algorithms reduce forgetting and maintain high sample efficiency by consolidating knowledge from the target Q-network to the current Q-network. Compared to baseline methods, our algorithms achieve comparable or better performance in both feature-based and image-based tasks while easing the burden of large experience replay buffers.
翻译:人工神经网络对一般功能近似很有希望,但对由于灾难性的遗忘而非独立或非身份分布的数据进行培训则具有挑战性。经验重放缓冲(深强化学习的标准组成部分)常常用来通过将经验储存在大型缓冲中,然后将其用于培训来减少遗忘并提高样本效率。然而,大型重放缓冲(尤其是对于内存能力有限的机载和边端装置而言)造成沉重的记忆负担。我们建议根据深重的Q-网络算法,采用记忆高效的强化学习算法来缓解这一问题。我们的算法通过将目标Q-网络的知识与当前的Q-网络结合起来,减少遗忘并保持高样本效率。与基线方法相比,我们的算法在基于特性和图像的任务中都实现了可比或更好的业绩,同时减轻了大型经验重置缓冲器的负担。</s>