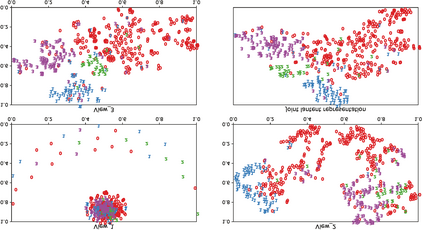
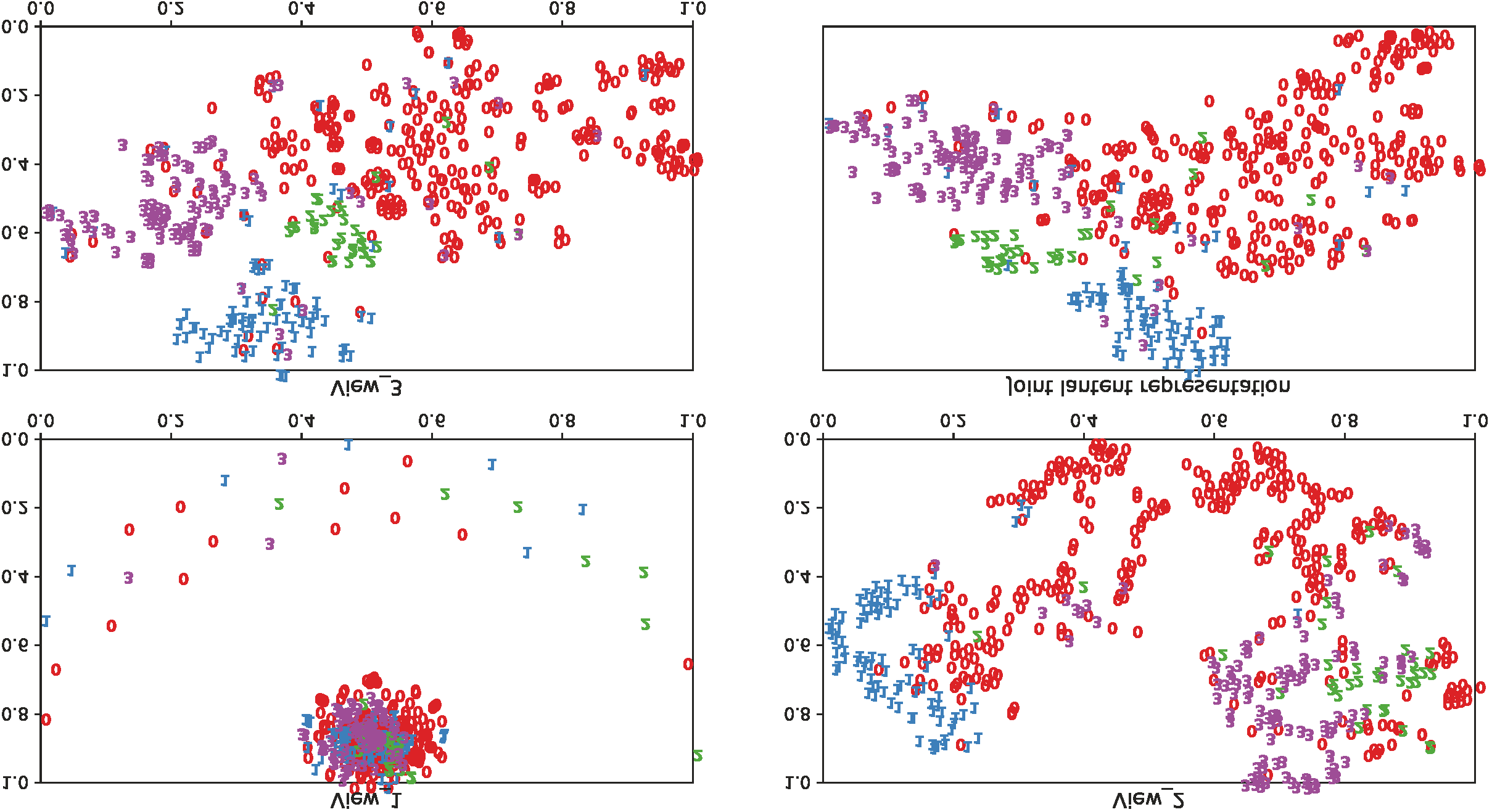
In this paper, we propose a novel Attentive Multi-View Deep Subspace Nets (AMVDSN), which deeply explores underlying consistent and view-specific information from multiple views and fuse them by considering each view's dynamic contribution obtained by attention mechanism. Unlike most multi-view subspace learning methods that they directly reconstruct data points on raw data or only consider consistency or complementarity when learning representation in deep or shallow space, our proposed method seeks to find a joint latent representation that explicitly considers both consensus and view-specific information among multiple views, and then performs subspace clustering on learned joint latent representation.Besides, different views contribute differently to representation learning, we therefore introduce attention mechanism to derive dynamic weight for each view, which performs much better than previous fusion methods in the field of multi-view subspace clustering. The proposed algorithm is intuitive and can be easily optimized just by using Stochastic Gradient Descent (SGD) because of the neural network framework, which also provides strong non-linear characterization capability compared with traditional subspace clustering approaches. The experimental results on seven real-world data sets have demonstrated the effectiveness of our proposed algorithm against some state-of-the-art subspace learning approaches.
翻译:在本文中,我们提议了一个新的 " 强化多视深潜空间网 " (AMVDSN),它深入探索多种观点提供的一致和特定观点的信息,并通过考虑每个观点通过关注机制获得的动态贡献,将这些信息融合起来。与大多数直接重建原始数据数据数据数据点的多视图子空间学习方法不同,或者仅仅在深浅空间学习代表性时考虑一致性或互补性,我们提议的方法寻求一种共同的潜在代表,明确考虑多种观点之间的共识和特定观点信息,然后对知识化的共同潜在代表方式进行子空间组合。此外,不同观点对代表性学习有不同的贡献,因此我们引入了关注机制,以产生每种观点的动态权重,这些观点在多视图子空间组合领域比以往的融合方法要好得多。 拟议的算法是直观的,而且可以很容易优化,因为神经网框架也提供了强大的非线性特征描述能力,与传统的子空间组合方法相比。七套真实世界数据集的实验结果显示了我们针对某些状态空间学习方法的拟议算法的有效性。