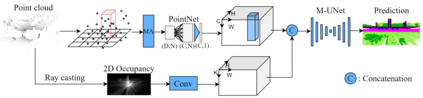
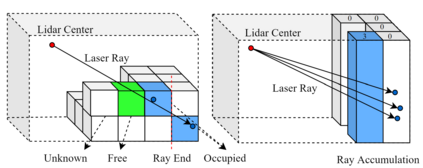
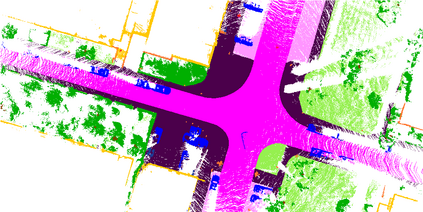
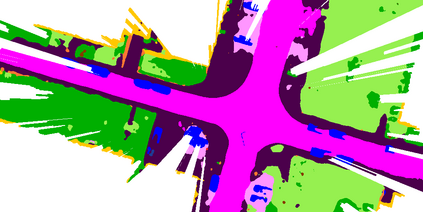
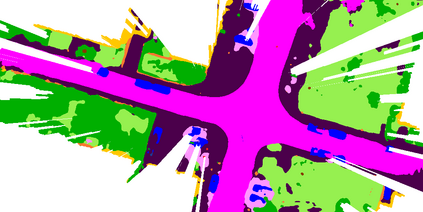
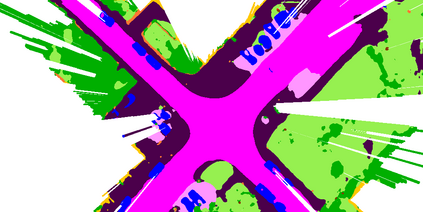
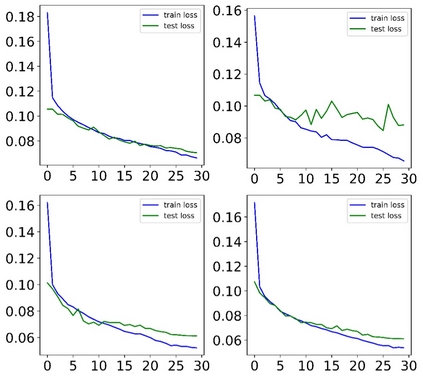
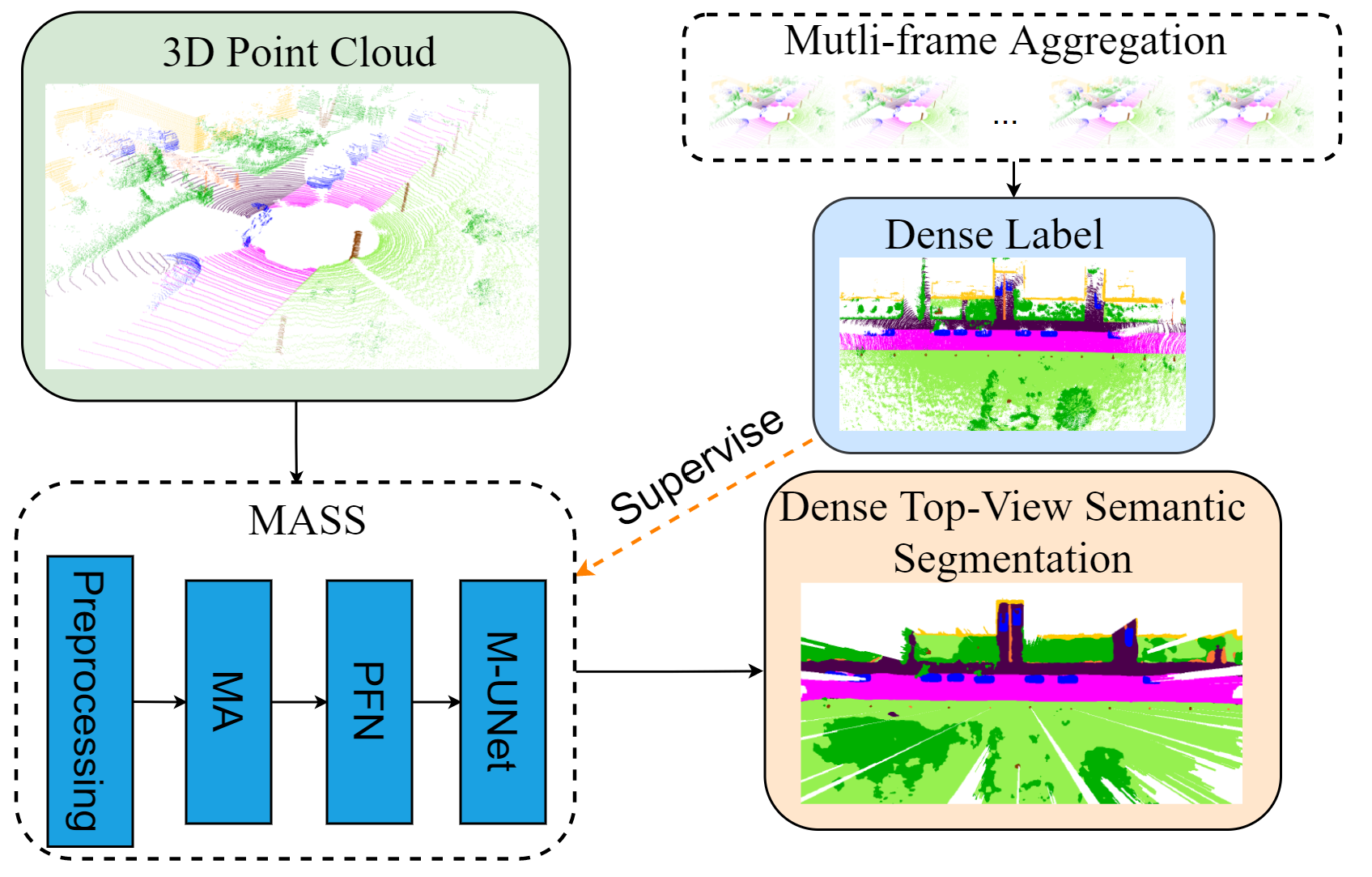
At the heart of all automated driving systems is the ability to sense the surroundings, e.g., through semantic segmentation of LiDAR sequences, which experienced a remarkable progress due to the release of large datasets such as SemanticKITTI and nuScenes-LidarSeg. While most previous works focus on sparse segmentation of the LiDAR input, dense output masks provide self-driving cars with almost complete environment information. In this paper, we introduce MASS - a Multi-Attentional Semantic Segmentation model specifically built for dense top-view understanding of the driving scenes. Our framework operates on pillar- and occupancy features and comprises three attention-based building blocks: (1) a keypoint-driven graph attention, (2) an LSTM-based attention computed from a vector embedding of the spatial input, and (3) a pillar-based attention, resulting in a dense 360-degree segmentation mask. With extensive experiments on both, SemanticKITTI and nuScenes-LidarSeg, we quantitatively demonstrate the effectiveness of our model, outperforming the state of the art by 19.0% on SemanticKITTI and reaching 30.4% in mIoU on nuScenes-LidarSeg, where MASS is the first work addressing the dense segmentation task. Furthermore, our multi-attention model is shown to be very effective for 3D object detection validated on the KITTI-3D dataset, showcasing its high generalizability to other tasks related to 3D vision.
翻译:所有自动化驱动系统的核心是感知周围环境的能力,例如,通过LIDAR序列的语义分解,通过LIDAR序列的语义分解取得了显著的进展,由于发行了大型数据集,如SemanticKITTI和nuScenes-LidarSeg。虽然大多数以前的工作侧重于LIDAR输入的稀疏分解,但密度高的输出面遮罩为自行驾驶的汽车提供了几乎完整的环境信息。在本文中,我们引入了MASS - 一个多机密的逻辑分解模型,专门为对驱动场进行密集的顶级理解。我们的框架在界碑-3的视野和占用特征上运作,并包括三个基于关注的建筑块:(1) 一个关键点驱动的图形注意,(2) 一个基于LSTM的注意,从嵌入空间输入的矢量的矢量上计算出一个密集的驱动力,导致一个稠密的360度分解面具。在Smantic-KITTI和nuScenes-LidarSeg中进行广泛的实验,我们在模型上展示其有效性,在高端点3-LIV上展示了艺术的状态,在30-SDI的Sxxxxxxxxxxxxxxxxxxxxxx