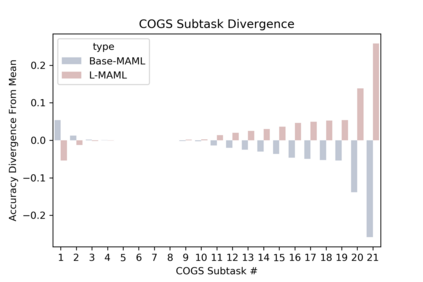
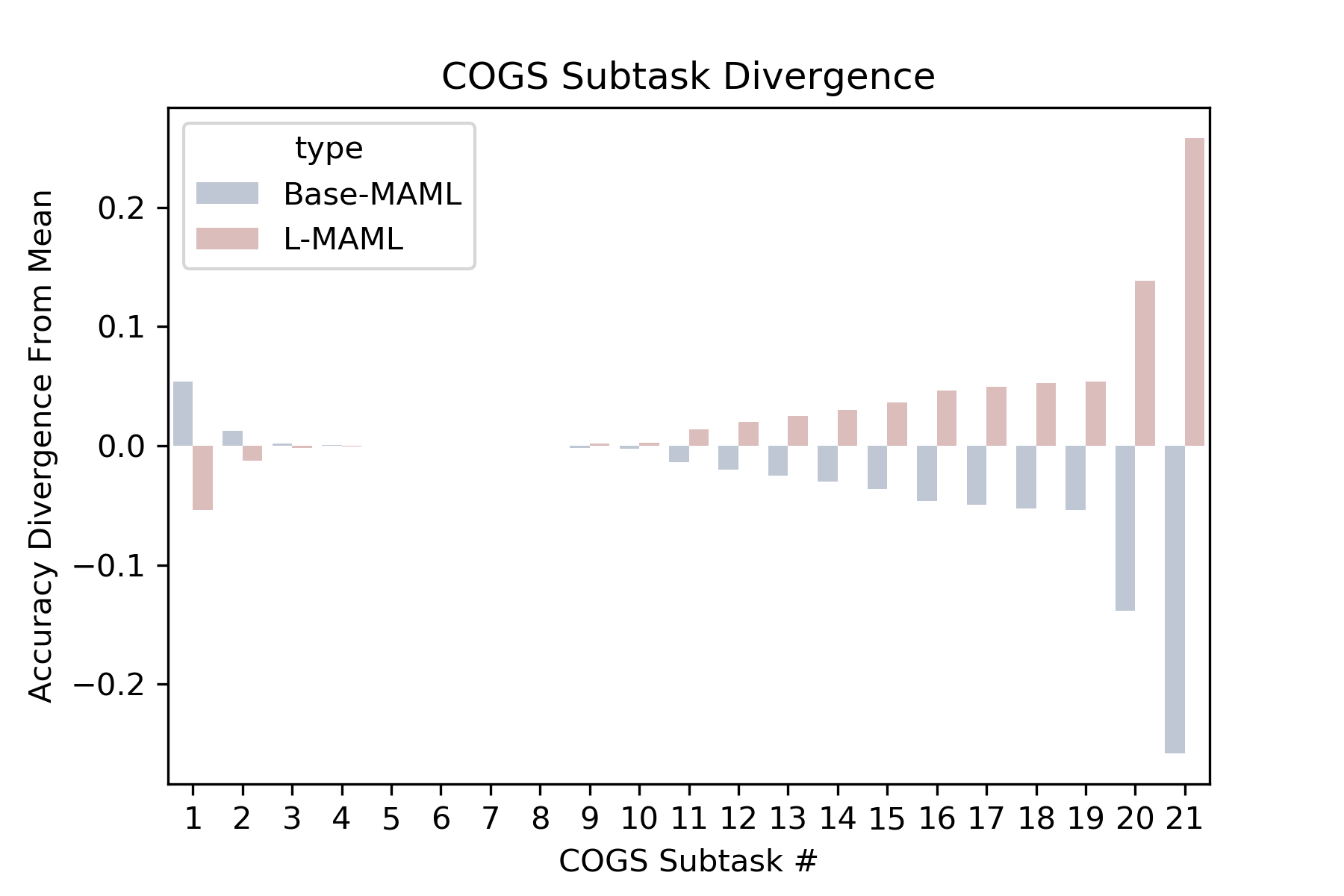
Natural language is compositional; the meaning of a sentence is a function of the meaning of its parts. This property allows humans to create and interpret novel sentences, generalizing robustly outside their prior experience. Neural networks have been shown to struggle with this kind of generalization, in particular performing poorly on tasks designed to assess compositional generalization (i.e. where training and testing distributions differ in ways that would be trivial for a compositional strategy to resolve). Their poor performance on these tasks may in part be due to the nature of supervised learning which assumes training and testing data to be drawn from the same distribution. We implement a meta-learning augmented version of supervised learning whose objective directly optimizes for out-of-distribution generalization. We construct pairs of tasks for meta-learning by sub-sampling existing training data. Each pair of tasks is constructed to contain relevant examples, as determined by a similarity metric, in an effort to inhibit models from memorizing their input. Experimental results on the COGS and SCAN datasets show that our similarity-driven meta-learning can improve generalization performance.
翻译:自然语言是构成性的; 句子的含义是其部分含义的函数。 这种属性使人类能够创造和解释新句子,在他们以前的经验之外大力推广。 神经网络已经证明与这种概括性斗争,特别是在为评估构成性而设计的任务方面表现不佳(即培训和测试分布方式不同,对于解决构成性战略来说微不足道); 它们在这些任务上的不良表现可能部分是由于监督性学习的性质,这种学习假定了从同一分布中获取培训和测试数据。 我们实施了一种强化的监督性学习模式,其目标直接优化于分配外的概括化。 我们通过对现有培训数据进行分抽样,为元化学习搭建了对齐的任务。 每对任务的设计都包含由类似指标确定的有关实例,以努力抑制模型的记忆性投入。 COGS和SCAN数据集的实验结果表明,我们类似驱动的元化学习可以改进一般化业绩。