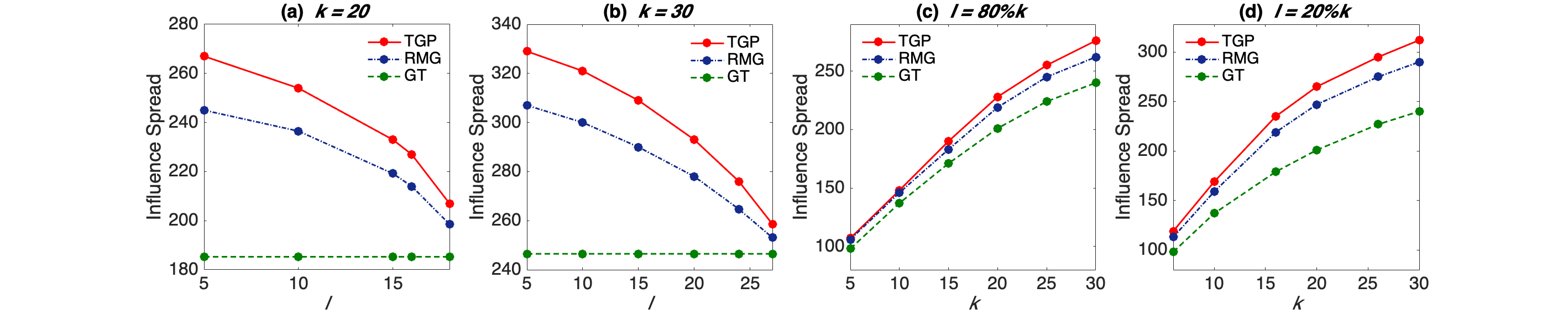
Meta-Learning has gained increasing attention in the machine learning and artificial intelligence communities. In this paper, we introduce and study an adaptive submodular meta-learning problem. The input of our problem is a set of items, where each item has a random state which is initially unknown. The only way to observe an item's state is to select that item. Our objective is to adaptively select a group of items that achieve the best performance over a set of tasks, where each task is represented as an adaptive submodular function that maps sets of items and their states to a real number. To reduce the computational cost while maintaining a personalized solution for each future task, we first select an initial solution set based on previously observed tasks, then adaptively add the remaining items to the initial solution set when a new task arrives. As compared to the solution where a brand new solution is computed for each new task, our meta-learning based approach leads to lower computational overhead at test time since the initial solution set is pre-computed in the training stage. To solve this problem, we propose a two-phase greedy policy and show that it achieves a $1/2$ approximation ratio for the monotone case. For the non-monotone case, we develop a two-phase randomized greedy policy that achieves a $1/32$ approximation ratio.
翻译:机器学习和人工智能界日益关注元学习。 在本文中, 我们引入并研究一个适应性子模块元学习问题。 我们的问题输入是一组项目, 每个项目都有一个最初未知的随机状态。 观察一个项目状态的唯一方法是选择该项目。 我们的目标是适应性地选择一组在一系列任务中表现最佳的项目, 每个任务都代表一个适应性子模块功能, 将各组项目及其状态映射成一个真实数字。 为了减少计算成本, 同时为每个未来任务维持个性化解决方案, 我们首先选择一套基于以往观察到的任务的初始解决方案, 然后在新任务到来时将剩余项目添加到初始解决方案中。 相比于为每项新任务计算品牌新解决方案的解决方案的解决方案, 我们基于元学习的方法导致在测试时间降低计算间接费用, 因为初始解决方案在培训阶段被预先配置。 为了解决这个问题, 我们提出一个两阶段的贪婪政策, 并显示它能达到一个1/2美分级的1美元水平, 将一个单级汇率转化为一个1美元的汇率。