【论文推荐】最新六篇主题模型相关论文—领域特定知识库、神经变分推断、动态和静态主题模型
【导读】专知内容组既昨天推出六篇主题模型(Topic Model)相关论文,今天又推出最新六篇主题模型(Topic Model)相关论文,欢迎查看!
7.A fast algorithm with minimax optimal guarantees for topic models with an unknown number of topics(一种适用于主题数量未知的主题模型的具有极小极大最优保证的快速算法)
作者:Xin Bing,Florentina Bunea,Marten Wegkamp
摘要:We propose a new method of estimation in topic models, that is not a variation on the existing simplex finding algorithms, and that estimates the number of topics K from the observed data. We derive new finite sample minimax lower bounds for the estimation of A, as well as new upper bounds for our proposed estimator. We describe the scenarios where our estimator is minimax adaptive. Our finite sample analysis is valid for any number of documents (n), individual document length (N_i), dictionary size (p) and number of topics (K), and both p and K are allowed to increase with n, a situation not handled well by previous analyses. We complement our theoretical results with a detailed simulation study. We illustrate that the new algorithm is faster and more accurate than the current ones, although we start out with a computational and theoretical disadvantage of not knowing the correct number of topics K, while we provide the competing methods with the correct value in our simulations.
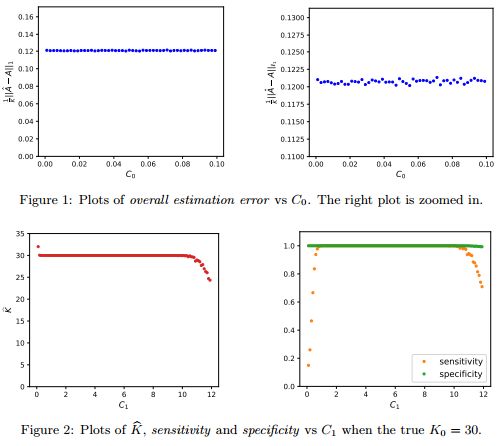
期刊:arXiv, 2018年6月13日
网址:
http://www.zhuanzhi.ai/document/aead5f2d6072eec4298d3a3a42dc1c52
8.Learning Multilingual Topics from Incomparable Corpus(从Incomparable 语料库学习多种语言的主题)
作者:Shudong Hao,Michael J. Paul
To appear in International Conference on Computational Linguistics (COLING), 2018
机构:University of Colorado
摘要:Multilingual topic models enable crosslingual tasks by extracting consistent topics from multilingual corpora. Most models require parallel or comparable training corpora, which limits their ability to generalize. In this paper, we first demystify the knowledge transfer mechanism behind multilingual topic models by defining an alternative but equivalent formulation. Based on this analysis, we then relax the assumption of training data required by most existing models, creating a model that only requires a dictionary for training. Experiments show that our new method effectively learns coherent multilingual topics from partially and fully incomparable corpora with limited amounts of dictionary resources.
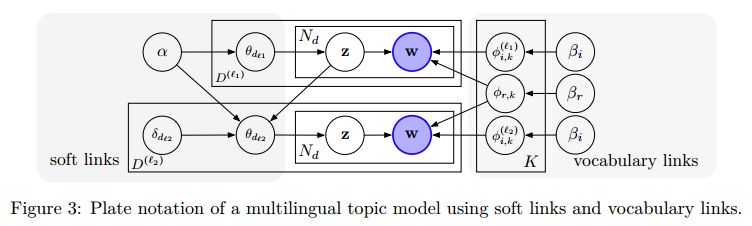
期刊:arXiv, 2018年6月12日
网址:
http://www.zhuanzhi.ai/document/f3ff5c54fc40990df5509a4dfe56ca6b
9.Topic Modelling of Empirical Text Corpora: Validity, Reliability, and Reproducibility in Comparison to Semantic Maps(经验文本语料库的主题建模:与语义图比较的有效性、可靠性和再现性)
作者:Tobias Hecking,Loet Leydesdorff
摘要:Using the 6,638 case descriptions of societal impact submitted for evaluation in the Research Excellence Framework (REF 2014), we replicate the topic model (Latent Dirichlet Allocation or LDA) made in this context and compare the results with factor-analytic results using a traditional word-document matrix (Principal Component Analysis or PCA). Removing a small fraction of documents from the sample, for example, has on average a much larger impact on LDA than on PCA-based models to the extent that the largest distortion in the case of PCA has less effect than the smallest distortion of LDA-based models. In terms of semantic coherence, however, LDA models outperform PCA-based models. The topic models inform us about the statistical properties of the document sets under study, but the results are statistical and should not be used for a semantic interpretation - for example, in grant selections and micro-decision making, or scholarly work-without follow-up using domain-specific semantic maps.
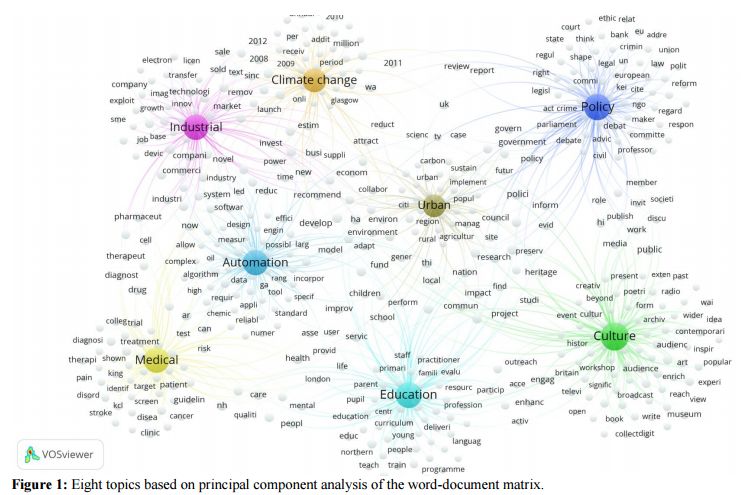
期刊:arXiv, 2018年6月4日
网址:
http://www.zhuanzhi.ai/document/75a8d716217e0ec585793ba7e9353382
10.Transfer Topic Labeling with Domain-Specific Knowledge Base: An Analysis of UK House of Commons Speeches 1935-2014(基于领域特定知识库的转移主题标注:英国下议院演讲的分析1935-2014)
作者:Alexander Herzog,Peter John,Slava Jankin Mikhaylov
机构:University of Essex,Clemson University
摘要:Topic models are among the most widely used methods in natural language processing, allowing researchers to estimate the underlying themes in a collection of documents. Most topic models use unsupervised methods and hence require the additional step of attaching meaningful labels to estimated topics. This process of manual labeling is not scalable and often problematic because it depends on the domain expertise of the researcher and may be affected by cardinality in human decision making. As a consequence, insights drawn from a topic model are difficult to replicate. We present a semi-automatic transfer topic labeling method that seeks to remedy some of these problems. We take advantage of the fact that domain-specific codebooks exist in many areas of research that can be exploited for automated topic labeling. We demonstrate our approach with a dynamic topic model analysis of the complete corpus of UK House of Commons speeches from 1935 to 2014, using the coding instructions of the Comparative Agendas Project to label topics. We show that our method works well for a majority of the topics we estimate, but we also find institution-specific topics, in particular on subnational governance, that require manual input. The method proposed in the paper can be easily extended to other areas with existing domain-specific knowledge bases, such as party manifestos, open-ended survey questions, social media data, and legal documents, in ways that can add knowledge to research programs.
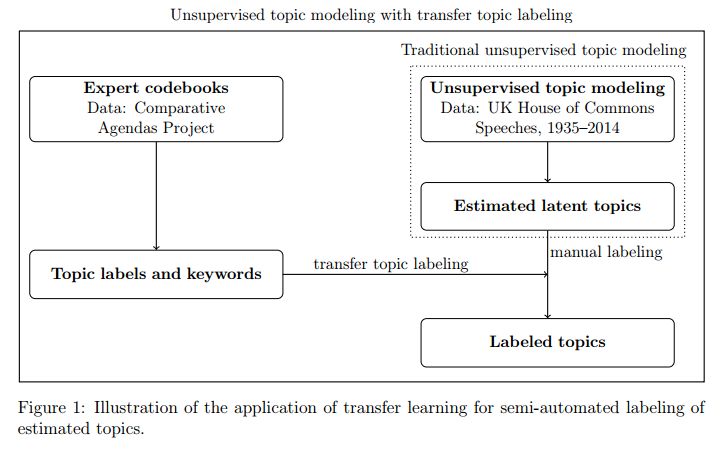
期刊:arXiv, 2018年6月3日
网址:
http://www.zhuanzhi.ai/document/a82f51ea5bb387b21aef962b41bdab0e
11.Discovering Discrete Latent Topics with Neural Variational Inference(用神经变分推断发现离散的潜在主题)
作者:Yishu Miao,Edward Grefenstette,Phil Blunsom
ICML 2017
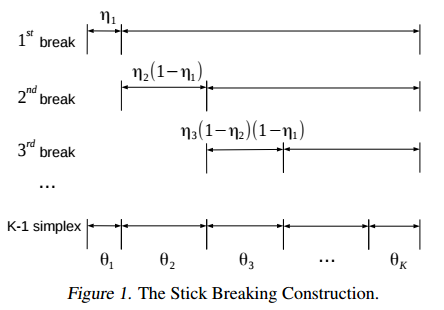
摘要:Topic models have been widely explored as probabilistic generative models of documents. Traditional inference methods have sought closed-form derivations for updating the models, however as the expressiveness of these models grows, so does the difficulty of performing fast and accurate inference over their parameters. This paper presents alternative neural approaches to topic modelling by providing parameterisable distributions over topics which permit training by backpropagation in the framework of neural variational inference. In addition, with the help of a stick-breaking construction, we propose a recurrent network that is able to discover a notionally unbounded number of topics, analogous to Bayesian non-parametric topic models. Experimental results on the MXM Song Lyrics, 20NewsGroups and Reuters News datasets demonstrate the effectiveness and efficiency of these neural topic models.
期刊:arXiv, 2018年5月22日
网址:
http://www.zhuanzhi.ai/document/6aa4ae7ebd57fbde824adc542cac50e8
12.Dynamic and Static Topic Model for Analyzing Time-Series Document Collections(基于动态和静态主题模型的时间序列文档集分析)
作者:Rem Hida,Naoya Takeishi,Takehisa Yairi,Koichi Hori
Accepted as ACL 2018 short paper
机构:The University of Tokyo
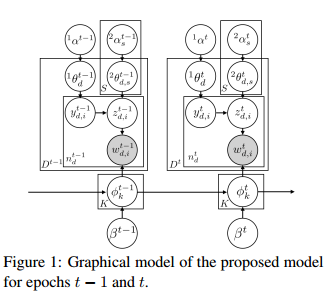
摘要:For extracting meaningful topics from texts, their structures should be considered properly. In this paper, we aim to analyze structured time-series documents such as a collection of news articles and a series of scientific papers, wherein topics evolve along time depending on multiple topics in the past and are also related to each other at each time. To this end, we propose a dynamic and static topic model, which simultaneously considers the dynamic structures of the temporal topic evolution and the static structures of the topic hierarchy at each time. We show the results of experiments on collections of scientific papers, in which the proposed method outperformed conventional models. Moreover, we show an example of extracted topic structures, which we found helpful for analyzing research activities.
期刊:arXiv, 2018年5月6日
网址:
http://www.zhuanzhi.ai/document/87133bf83a96578b1bcbf06c62d31a38
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知





