
题目: Meta-Learning Initializations for Low-Resource Drug Discovery
摘要:
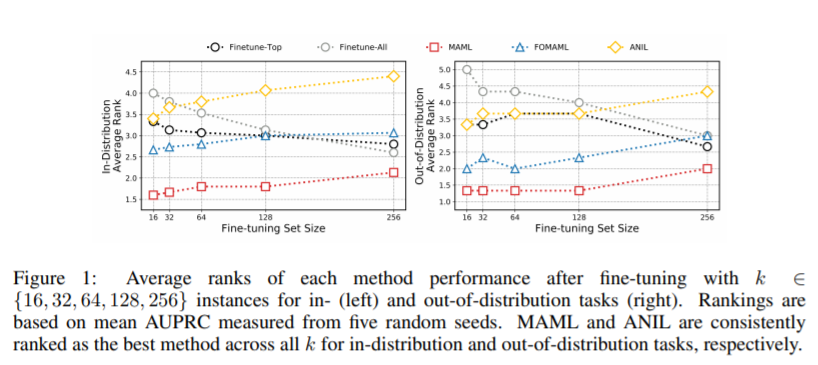
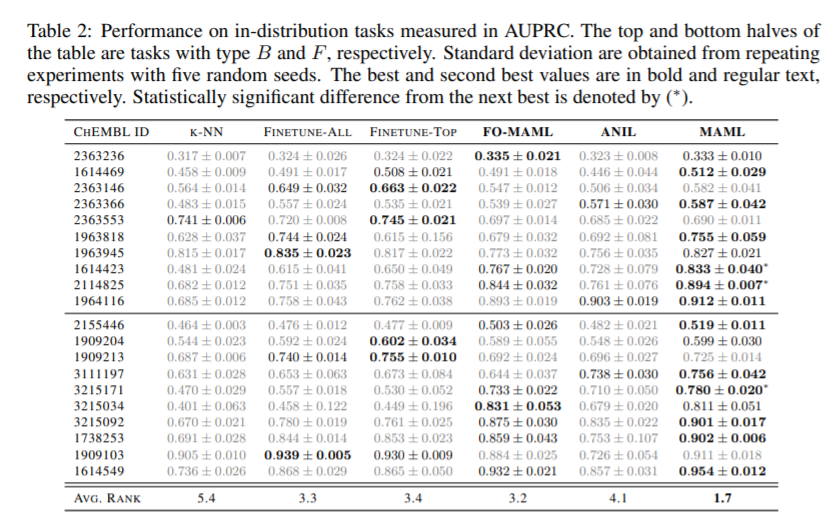
建立硅模型来预测化学性质和活性是药物发现的关键一步。然而,药物发现项目的特点是标记数据有限,这阻碍了深度学习在这种情况下的应用。与此同时,元学习的进步使得在小样本学习基准中的最优表现成为可能,这自然引发了这样一个问题:元学习能否提高在低资源药物发现项目中的深度学习性能?在这项工作中,我们评估了模型不可知元学习(MAML)算法的效率——以及它的变体FO-MAML和ANIL——在学习预测化学性质和活性方面的效率。使用ChEMBL20数据集来模拟低资源设置,我们的基准测试表明,在20个分布任务中的16个任务和所有分布任务中,元初始化的性能与多任务训练前基线相当或优于多任务训练基线,分别为AUPRC提供7.2%和14.9%的平均改进。最后,我们观察到,元初始化一致地在k∈{16,32,64,128,256}实例的微调集上产生性能最佳的模型。
成为VIP会员查看完整内容
相关内容

专知会员服务
23+阅读 · 2020年4月22日
Arxiv
5+阅读 · 2019年8月27日
Arxiv
8+阅读 · 2018年5月12日


相关VIP内容
专知会员服务
23+阅读 · 2020年4月22日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年8月27日
Arxiv
8+阅读 · 2018年5月12日