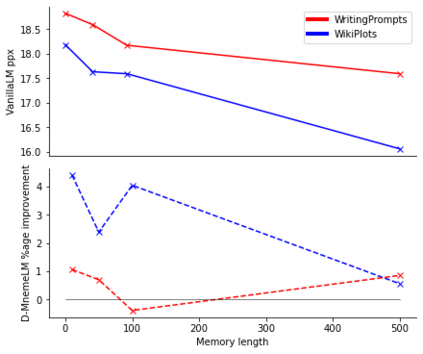
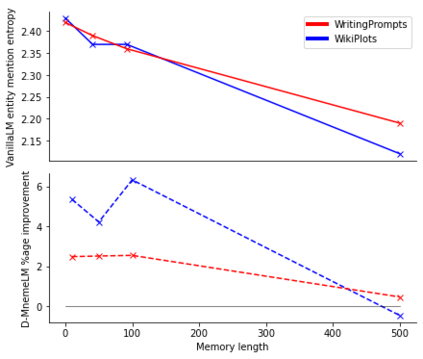
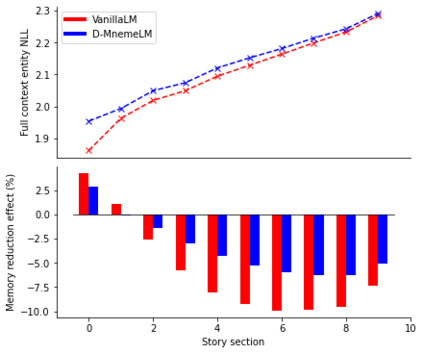
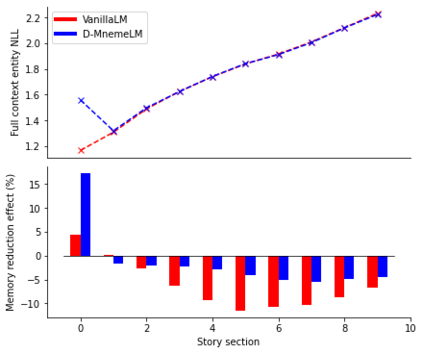
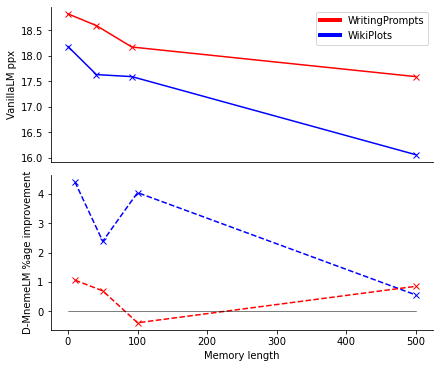
Large pre-trained language models (LMs) have demonstrated impressive capabilities in generating long, fluent text; however, there is little to no analysis on their ability to maintain entity coherence and consistency. In this work, we focus on the end task of narrative generation and systematically analyse the long-range entity coherence and consistency in generated stories. First, we propose a set of automatic metrics for measuring model performance in terms of entity usage. Given these metrics, we quantify the limitations of current LMs. Next, we propose augmenting a pre-trained LM with a dynamic entity memory in an end-to-end manner by using an auxiliary entity-related loss for guiding the reads and writes to the memory. We demonstrate that the dynamic entity memory increases entity coherence according to both automatic and human judgment and helps preserving entity-related information especially in settings with a limited context window. Finally, we also validate that our automatic metrics are correlated with human ratings and serve as a good indicator of the quality of generated stories.
翻译:受过培训的大型语言模型(LMS)在生成长而流利的文本方面表现出了令人印象深刻的能力;然而,关于它们保持实体一致性和一致性的能力,几乎没有甚至根本没有分析。在这项工作中,我们侧重于叙述生成的最终任务,并系统地分析生成故事的远程实体一致性和一致性。首先,我们提出一套衡量实体使用率模型绩效的自动衡量标准。根据这些指标,我们量化了当前LMS的局限性。接下来,我们提议通过使用与辅助实体有关的损失来引导读本并写到记忆中,增加一个具有动态实体记忆的预培训LM(LM),以端至端的方式,我们提议使用与实体有关的损失来指导读本并写到记忆中。我们表明,动态实体记忆根据自动和人文的判断,提高实体的一致性,并帮助保存实体相关信息,特别是在环境窗口有限的情况下。最后,我们还确认,我们的自动计量标准与人类评级相关,并作为生成故事质量的良好指标。