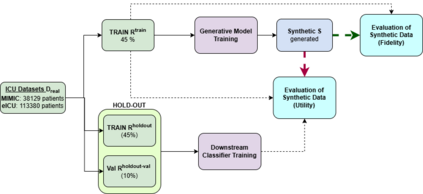
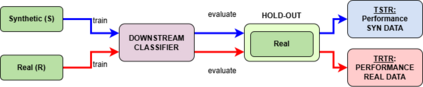
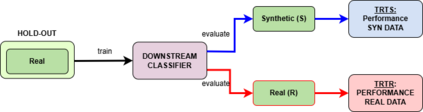
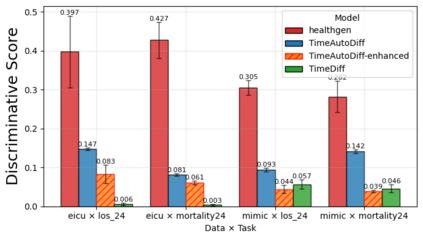
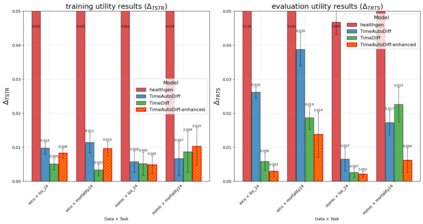
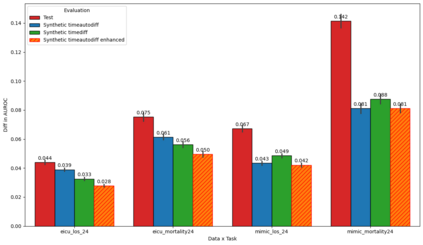
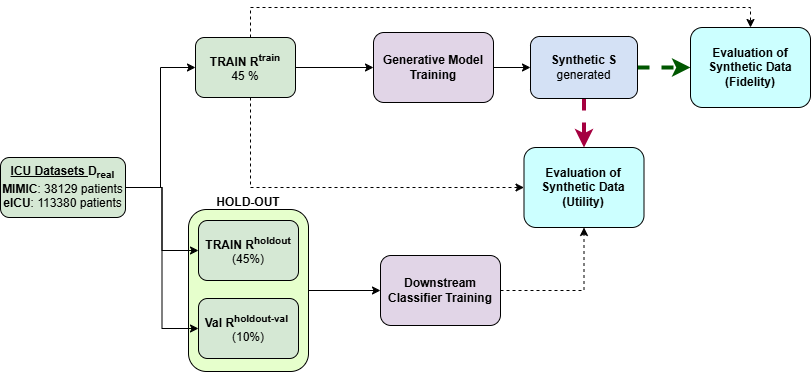
We present a novel framework for leveraging synthetic ICU time-series data not only to train but also to rigorously and trustworthily evaluate predictive models, both at the population level and within fine-grained demographic subgroups. Building on prior diffusion and VAE-based generators (TimeDiff, HealthGen, TimeAutoDiff), we introduce \textit{Enhanced TimeAutoDiff}, which augments the latent diffusion objective with distribution-alignment penalties. We extensively benchmark all models on MIMIC-III and eICU, on 24-hour mortality and binary length-of-stay tasks. Our results show that Enhanced TimeAutoDiff reduces the gap between real-on-synthetic and real-on-real evaluation (``TRTS gap'') by over 70\%, achieving $\Delta_{TRTS} \leq 0.014$ AUROC, while preserving training utility ($\Delta_{TSTR} \approx 0.01$). Crucially, for 32 intersectional subgroups, large synthetic cohorts cut subgroup-level AUROC estimation error by up to 50\% relative to small real test sets, and outperform them in 72--84\% of subgroups. This work provides a practical, privacy-preserving roadmap for trustworthy, granular model evaluation in critical care, enabling robust and reliable performance analysis across diverse patient populations without exposing sensitive EHR data, contributing to the overall trustworthiness of Medical AI.
翻译:暂无翻译