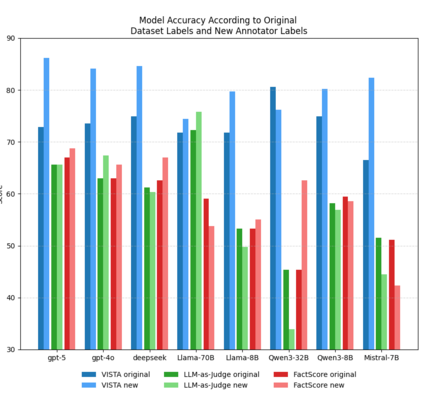
Hallucination--defined here as generating statements unsupported or contradicted by available evidence or conversational context--remains a major obstacle to deploying conversational AI systems in settings that demand factual reliability. Existing metrics either evaluate isolated responses or treat unverifiable content as errors, limiting their use for multi-turn dialogue. We introduce VISTA (Verification In Sequential Turn-based Assessment), a framework for evaluating conversational factuality through claim-level verification and sequential consistency tracking. VISTA decomposes each assistant turn into atomic factual claims, verifies them against trusted sources and dialogue history, and categorizes unverifiable statements (subjective, contradicted, lacking evidence, or abstaining). Across eight large language models and four dialogue factuality benchmarks (AIS, BEGIN, FAITHDIAL, and FADE), VISTA substantially improves hallucination detection over FACTSCORE and LLM-as-Judge baselines. Human evaluation confirms that VISTA's decomposition improves annotator agreement and reveals inconsistencies in existing benchmarks. By modeling factuality as a dynamic property of conversation, VISTA offers a more transparent, human-aligned measure of truthfulness in dialogue systems.
翻译:暂无翻译