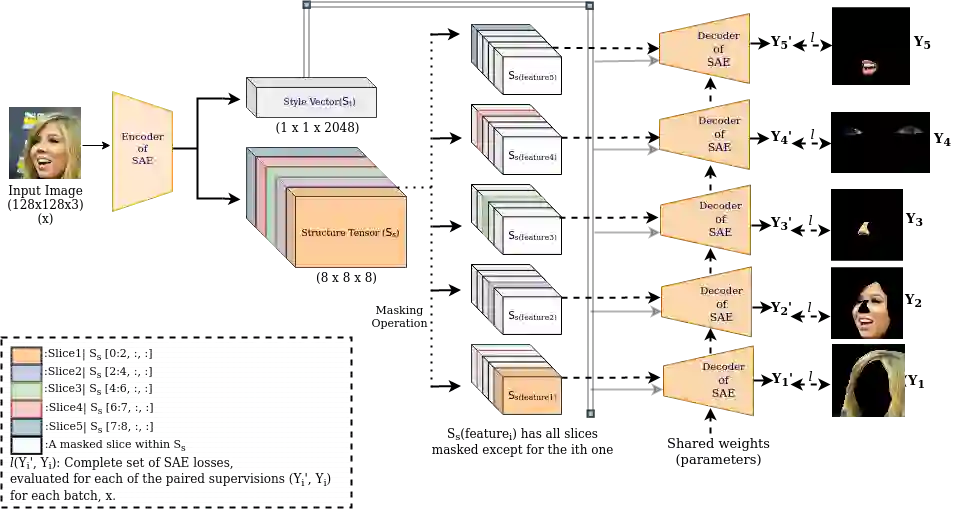
With the advent of an increasing number of Augmented and Virtual Reality applications that aim to perform meaningful and controlled style edits on images of human faces, the impetus for the task of parsing face images to produce accurate and fine-grained semantic segmentation maps is more than ever before. Few State of the Art (SOTA) methods which solve this problem, do so by incorporating priors with respect to facial structure or other face attributes such as expression and pose in their deep classifier architecture. Our endeavour in this work is to do away with the priors and complex pre-processing operations required by SOTA multi-class face segmentation models by reframing this operation as a downstream task post infusion of disentanglement with respect to facial semantic regions of interest (ROIs) in the latent space of a Generative Autoencoder model. We present results for our model's performance on the CelebAMask-HQ and HELEN datasets. The encoded latent space of our model achieves significantly higher disentanglement with respect to semantic ROIs than that of other SOTA works. Moreover, it achieves a 13% faster inference rate and comparable accuracy with respect to the publicly available SOTA for the downstream task of semantic segmentation of face images.
翻译:随着越来越多的强化和虚拟现实应用的出现,这些应用旨在对人脸图像进行有意义和受控的编辑,对面部图像进行剖析,以制作准确和细微的语义分解图的动力比以往任何时候要大得多。艺术国家(SOTA)很少采用解决这一问题的方法,而是将面部结构或其他面部属性,如表情和深层分类结构中的表情和表情等属性纳入其中。我们这项工作的目的是消除SOTA多层面部分解模型所需的前期和复杂的预处理操作,为此将这一操作重新组合成一个下游任务,将面部图像与Geneoration Autencoder模型潜在空间的相融合。我们介绍了我们的模型在CeebAMsk-HQ和HELEN数据集中的性能。我们模型的潜在空间与SOTA多级面部图谱模型的内置和复杂前处理操作相交织得比其他SOTA图像的正文分立性要高得多。此外,SOTA图像的下游图段比可比较性高。