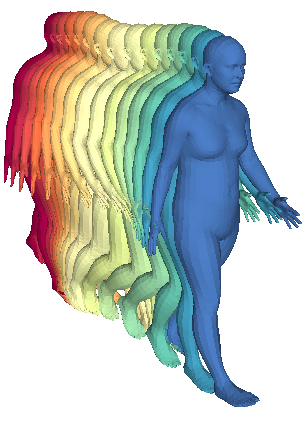
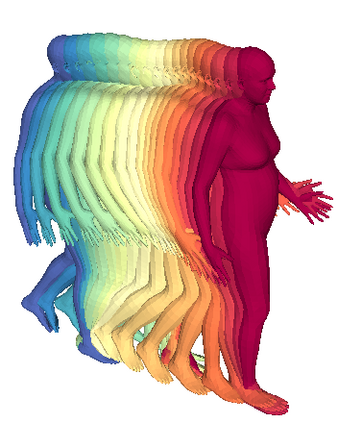
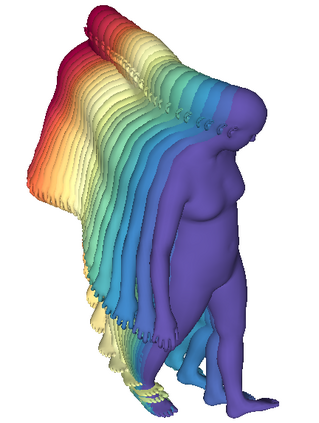
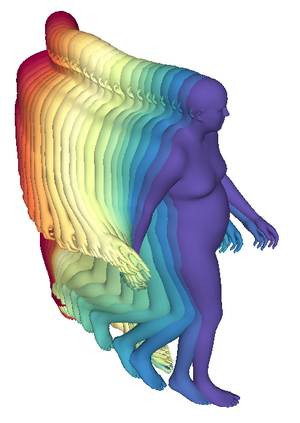
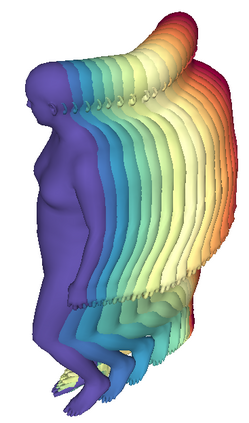
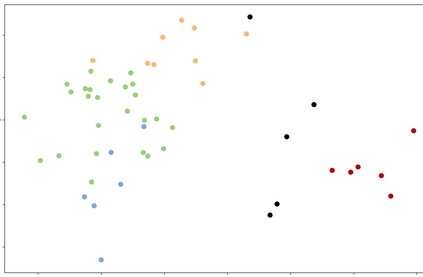
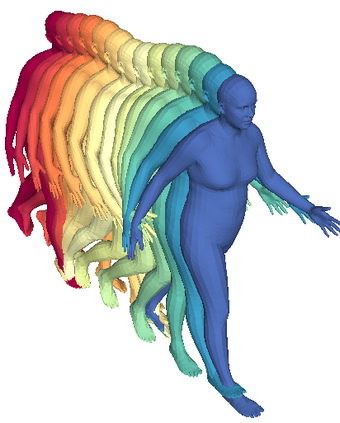
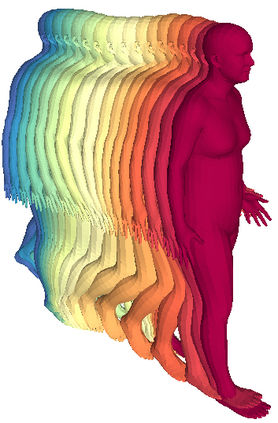
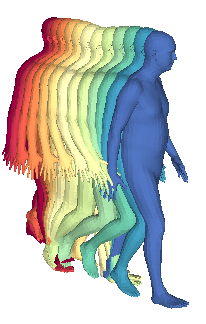
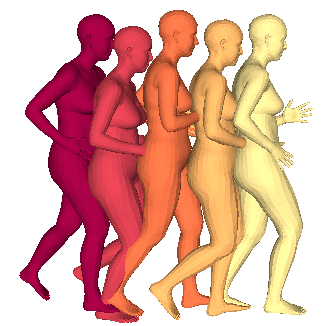
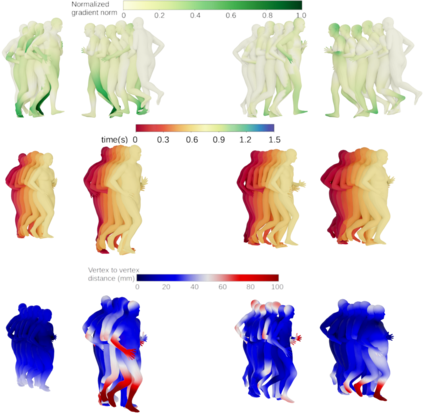
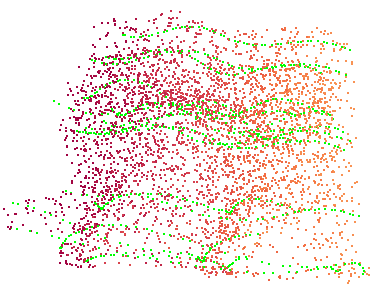
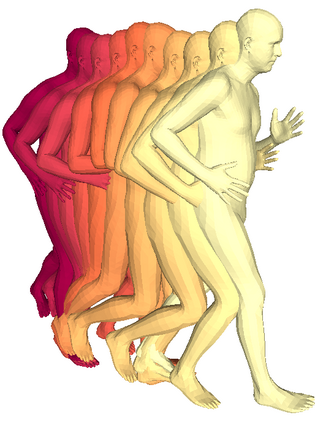
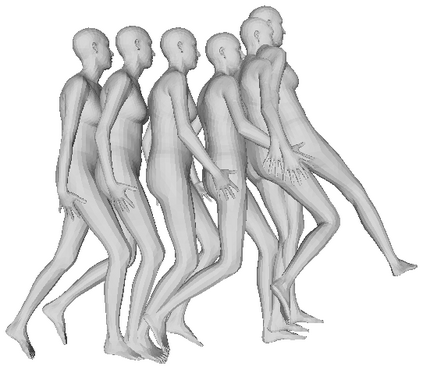
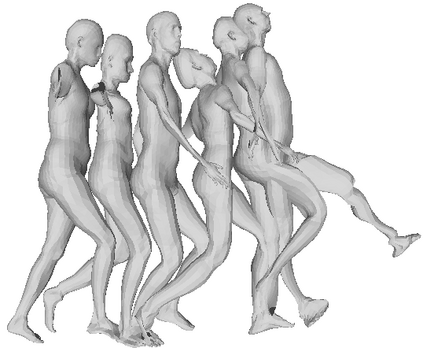
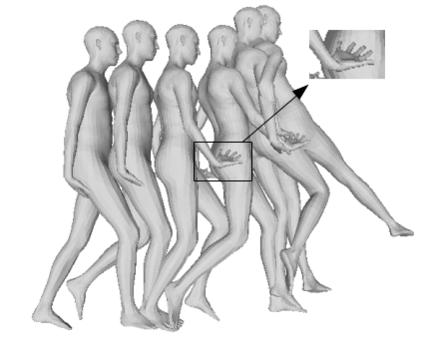
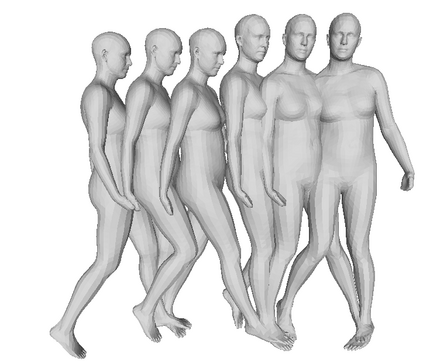
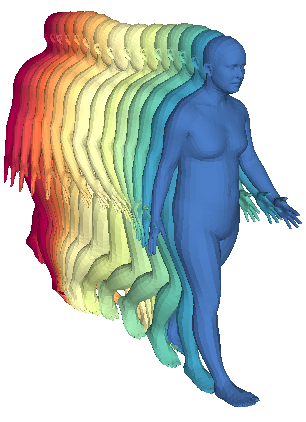
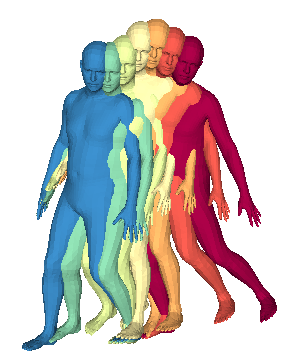We propose a framework to learn a structured latent space to represent 4D human body motion, where each latent vector encodes a full motion of the whole 3D human shape. On one hand several data-driven skeletal animation models exist proposing motion spaces of temporally dense motion signals, but based on geometrically sparse kinematic representations. On the other hand many methods exist to build shape spaces of dense 3D geometry, but for static frames. We bring together both concepts, proposing a motion space that is dense both temporally and geometrically. Once trained, our model generates a multi-frame sequence of dense 3D meshes based on a single point in a low-dimensional latent space. This latent space is built to be structured, such that similar motions form clusters. It also embeds variations of duration in the latent vector, allowing semantically close sequences that differ only by temporal unfolding to share similar latent vectors. We demonstrate experimentally the structural properties of our latent space, and show it can be used to generate plausible interpolations between different actions. We also apply our model to 4D human motion completion, showing its promising abilities to learn spatio-temporal features of human motion.
翻译:我们建议一个框架来学习一个结构化的潜在空间, 以代表 4D 人体运动, 每个潜伏矢量将整个 3D 人类形状的完整运动编码成。 一方面, 若干数据驱动的骨骼动动模型存在, 提出时间密集的运动空间, 但以几何分散的运动形态为根据。 另一方面, 有许多方法可以构建密度为 3D 几何的形状空间, 但用于静态框架 。 我们把两个概念汇集在一起, 提议一个时间密集的和几何性的运动空间 。 一旦经过培训, 我们的模型将生成一个密度为 3D 的多框架序列, 以低维潜伏空间中的单点为基础。 这种潜伏空间是建构成结构的, 类似运动的组合组。 它还嵌入潜伏于潜伏矢量的长度变化中, 允许仅因时间变化而产生相近的静态矢量。 我们实验性地展示我们潜伏空间的结构特性, 并展示它可用于在不同动作之间产生可信的内推论。 我们还将模型应用于 4D 人类运动完成 。