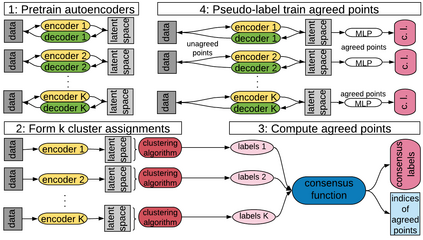
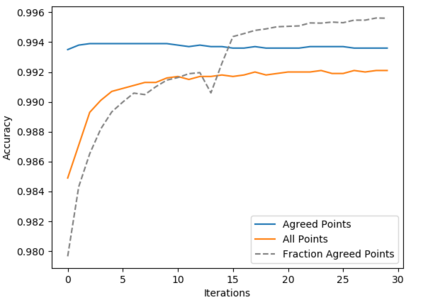
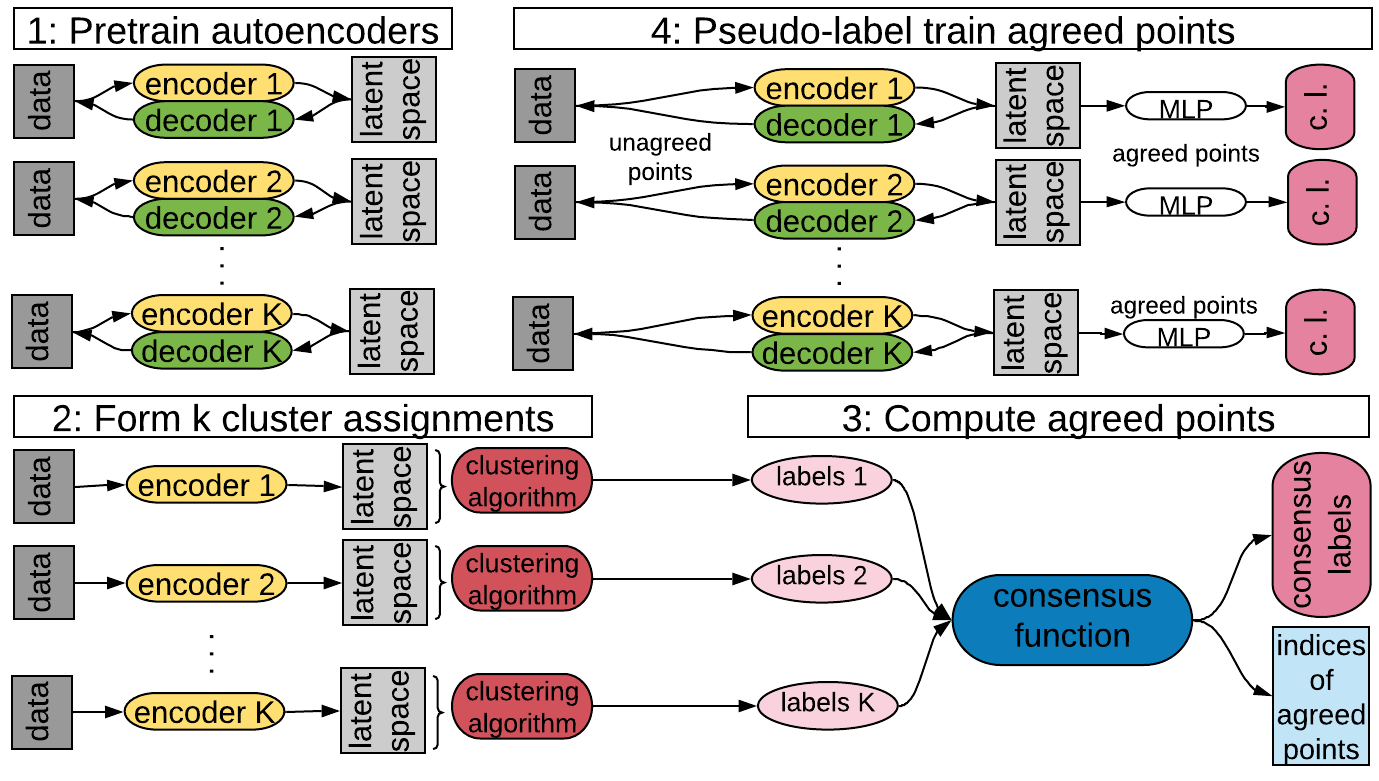
Deep neural networks (DNNs) offer a means of addressing the challenging task of clustering high-dimensional data. DNNs can extract useful features, and so produce a lower dimensional representation, which is more amenable to clustering techniques. As clustering is typically performed in a purely unsupervised setting, where no training labels are available, the question then arises as to how the DNN feature extractor can be trained. The most accurate existing approaches combine the training of the DNN with the clustering objective, so that information from the clustering process can be used to update the DNN to produce better features for clustering. One problem with this approach is that these ``pseudo-labels'' produced by the clustering algorithm are noisy, and any errors that they contain will hurt the training of the DNN. In this paper, we propose selective pseudo-label clustering, which uses only the most confident pseudo-labels for training the~DNN. We formally prove the performance gains under certain conditions. Applied to the task of image clustering, the new approach achieves a state-of-the-art performance on three popular image datasets. Code is available at https://github.com/Lou1sM/clustering.
翻译:深心神经网络( DNN) 提供了应对高维数据集集这一艰巨任务的手段。 DNN 能够提取有用的功能,从而产生更适合集束技术的较低维度的表达方式。 由于集束通常在完全无人监督的环境中进行,没有培训标签,因此产生了如何培训 DNN 特征提取器的问题。 最准确的现有方法将DNN 培训与集束目标结合起来, 使集成过程的信息能够用来更新 DNN, 从而产生更好的集束特性。 这种方法的一个问题是, 由集束算法制作的这些“ pseudo- lables” 是一个噪音问题, 以及它们中包含的任何错误将损害 DNN 的培训。 在本文中, 我们提出选择性的假标签组合, 仅使用最自信的假标签来培训 ~ DNNN。 我们正式证明在某些条件下的绩效收益。 用于图像集集成的任务, 新的方法在三种流行的图像集图像数据集上实现状态- 。